
都说AI绘画来势汹汹,但论创意,还是人类玩得花。
不信来看看这张乍一看平平无奇,却在网上疯传的AI生成美女图片:

图源:抖音账号@麦橘MAJIC
赶紧按下手机截图键,看看原图和缩略图的对比,你就能窥破玄机:

是的没错!
这张AI生成的图片里,偷摸在光影中融进去了两个汉字。
这两天,类似图片疯狂刷屏。各个平台上被争相讨论的,不仅有上面的🐮
姐,还有下面这位diao哥。
 △
△
图源:抖音账号@麦橘MAJIC
以及这位把
AI“穿”在身上的的红毛衣小姐姐:
 △
△
图源:抖音账号@麦橘MAJIC
建议大家在手机上手动缩放一下这些图,缩得越小,图片夹带的文字能更清晰。
还有网友给了别的“认字”秘诀,比如摘下你的近视眼镜:

呼声最高的评论有两种,一种是“牛哇牛哇”的感叹,另一种是嗷嗷待哺的“蹲教程”。
所以,这些又牛又diao的图,是怎么做出来的?
ControlNet又立大功
要让光影在图片甚至人物衣物上“写字”,利用的工具还是那套神奇的AI绘图组合:
Stable Diffusion+ControlNet。
作为最火爆的两个AI绘画工具之一,Stable Diffusion已经风靡一年,热度不减,已经被大伙儿熟知和玩坏了。
所以想重点介绍一下ControlNet,这家伙是Stable Diffusion的一个AI插件。
今年春天,ControlNet因为能够搞定AI原本无法控制的手部细节、整体架构,一炮而红,被网友们戏称为“AI绘画细节控制大师”。

Stable Diffusion根据提示词生成图像显然太过随机,ControlNet提供的功能,恰好是一种更精确地限制图像生成范围的办法。
究其原理,本质上是给予训练扩散模型增加一个额外的输入,从而控制它生成的细节。
“额外的输入”可以是各种类型的,包括草图、边缘图像、语义分割图像、人体关键点特征、霍夫变换检测直线、深度图、人体骨骼等。
Stable Diffusion搭配ControlNet的整个过程中,第一步是预处理器生成图像,第二步让这些图像经过ControlNet模型的处理,第三步时,将图像输入到Stable Diffusion中,生成最后展现在用户面前的版本。
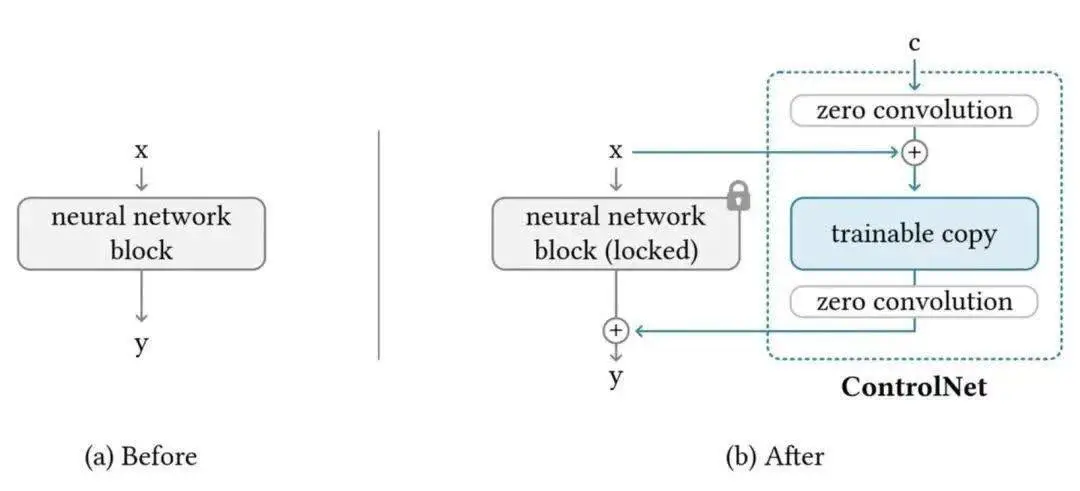
单说ControlNet的整体思路,就是先复制一遍扩散模型的权重,得到一个可训练副本(trainable copy)。
原本扩散模型经过几十亿张图片的预训练,参数处于被“锁定”的状态。但这个可训练副本,只需要在特定任务的小数据集上训练,就能学会条件控制。
而且就算数据量很少——哪怕少于5万张——模型经过训练后,条件控制生成的效果也贼拉棒。
比如diao哥和姐的那几张图中,它主要起到的作用,就是负责确保文字作为光影、衣服图案等,“放进”了图像中。
抖音原作者表示,最后还用上了ControlNet tile模型,这个模型主要负责增加描绘的细节,并且保证在增加降噪强度时,原图的构图也不会被改变。
也有AI爱好者“另辟蹊径”,表示要得到如图效果,可以用上ControlNet brightness模型(control_v1p_sd15_brightness)。
这个模型的作用,是控制深度信息,对稳定扩散进行亮度控制,即允许用户对灰度图像着色,或对生成的图像重新着色。
一方面,能让图片和文字融合得更好。
另一方面,能是让图片尤其是文字部分亮起来,这样光影写出的文字看起来会更加明显。
眼尖的小伙伴们可能已经发现了,给图片加汉字光影的整体思路,跟前几天同样爆火的图像风格二维码如出一辙。
不仅看起来不像个“正经”二维码,用手机扫扫还能真的跳转到有效网页。
不仅有动漫风,还有3D立体、水墨风、浮世绘风、水彩风、PCB风格……
同样在Reddit等平台上引起“哇”声一片:

不过略有不同的是,这些二维码背后不仅需要用到Stable Diffusion和ControlNet(包括brightness模型),还需要LoRA的配合。
AI大手子分享教程
光影效果爆火之后,推特上很快有AI大手子站出来表示愿意分享手把手教程。

大概思路非常简单,分为3个重要步骤:
第一步,安装Stable Diffusion和ControlNet;
第二步,在Stable Diffusion中进行常规的文生图步骤;
第三步,启用ControlNet,重点调整Control Weight和Ending Control Step两个参数。
运用这个方法,不仅可以完成人像和光影文字的融合,城市夜景什么的,也妥妥的。

大佬还在教程里温馨提示了一下:
写提示词时,尽量不要用一些例如特写人像之类的提示词,不然文字或者图案就会盖在人脸上,很难看.
有了手把手教学,加上同思路的AI二维码制作秘籍早已公开,网友们已经玩嗨了:




△
图源微博、抖音网友,为AI生成作品
你说说,这效果,这动手能力,谁看了不说一句NB呢?(doge)
来源:量子位
给这篇文章的作者打赏
 微信扫一扫打赏
微信扫一扫打赏 支付宝扫一扫打赏
支付宝扫一扫打赏





