最近ChatGPT大火,在世界范围内掀起轩然大波,这玩意儿的出现可说是划时代,所以一直都想来谈谈。
大家可能觉得我是个文科生,但事实上我对人工智能、大数据之类的技术非常关注,历史上但凡出现了某种能够改变世界运作方式的技术,都会对当时的哲学、宗教乃至整个社会文化造成极大的影响——研究社会文化的发展脉络决不可忽视技术的演进。
在ChatGPT出现之前,有些人大概会觉得人工智能距离我们很远,对人工智能的认识仅限于下围棋的AlphaGo——其实这些年来人工智能技术的应用早就改变了我们的生活,只不过大多数人在使用这些技术的时候,完全没有意识到这些属于“人工智能”。比方几乎每台智能手机都拥有的语音识别、面容识别,便属于人工智能范畴中最基础的信息识别技术,能够从声音、图像中提取并识别信息,这是机器对人类感知、认知能力的低级模拟。
有了“感知”作为基础,就能发展出分析决策等更高级的能力,这类人工智能也早已在我们的日常生活中大量应用。从给你定向推送广告的大数据算法、高效的信息化物流管理,到能够在限定路况下完全自主操作的L4级自动驾驶,都使用了许多人工智能相关技术。
人工智能的优势在于海量的信息处理能力,并且永远不会分心、疲倦,随着信息处理量越多,决策能力也随之不断增强。虽然目前人工智能在大部分时候还只能作为一个辅助决策工具,但实现全面决策只是迟早的事情。比方说我对自动驾驶的前景就很看好,这一技术成熟后能够大大提高效率节约能源。有人可能会说:自动驾驶不是照样出车祸吗?是的,可你们难道忘了人类驾驶员也会出车祸吗?自动驾驶并不需要绝对完美,只要发生车祸的概率低于人类驾驶员就足够取代人类了。
然而我不得不承认,我过去对人工智能的认识还是有些狭隘,局限于大数据算法、决策类的人工智能;虽然我平时经常使唤小爱同学,但小爱同学这种水平的语音助手在我看来只是一个能够服从语音指令的程序,还远远未到“智能”的地步。我以前总觉得机器想要像人类一样说话是件难如登天的事情,因而完全没想到这么快就出现了ChatGPT这种能够处理自然语言的人工智能,而且其知识储备比我想象中的人工智能更为强大。ChatGPT的划时代之处在于,它是第一个能够通过图灵测试(Turing Test)、并开放给公众使用的人工智能服务——当一部机器跟你对话时能够让你无法区别它究竟是人类还是机器,就可以认为它通过了图灵测试;图灵测试并不需要骗过所有人,只要能骗过一部分人就够了。

当你分不清对面跟你交谈的是人还是机器时,就能够认为这台机器通过了图灵测试。进行图灵测试的都是专业评估人员
这一新事物的问世令我非常震惊,我看了大量关于ChatGPT的评测和讨论,并研究了其原理。这玩意儿基于建立在人工神经网络上的大型变换语言模型,能够通过深度学习生成人类可以理解的自然语言。它的学习过程有人类训练员进行监督,以确保它的表达及三观正确;ChatGPT公开上线之后,用户也能对它的回复进行反馈,对它进行进一步的训练和微调——也就是说跟越多的人聊过天之后,它就越会聊天。
随后我用印度电话号码注册了一个ChatGPT账号,我没什么兴趣跟它闲聊扯淡,但我很想看看它对于一些我长期关注的问题会有何种见解。由于之前已经看了许多评测介绍,ChatGPT的表现基本上跟我预期的差不多。就我个人的使用体验而言,我得说ChatGPT快速归纳和整理信息的能力很强,回答问题很有条理,擅长罗列“一二三四”,这些“一二三四”大都可以直接作为展开论述的提纲;ChatGPT在某些情况下可以取代搜索引擎,有些问题直接问它比去搜索引擎上找更为便捷;但由于ChatGPT没有接入实时数据(目前数据截至2021年12月),无法提供最近的新闻时事相关信息,或对其做出评论。
我太太开玩笑地说,以后你可以让ChatGPT帮你写文章了。然而可惜的是,ChatGPT擅长的资料检索、归纳整理,恰好也是我十分擅长的;虽然它的效率很高,但就目前看来,它的可靠性和准确性还不足以让我能够充分信任它——有时候它会一本正经地捏造出看起来似是而非的答案;有时候则会给出一大段看似冗长实则空洞的回复;在涉及到需要进行对比的情况它会毫不犹豫地和稀泥,哪边都不得罪。因此我无法完全相信它提供的回答,只会将其作为一个参考。我发现ChatGPT自己也知道回答得不一定对,有时候会在回答完问题的最后,鸡贼地给自己留一条模棱两可的退路,例如说自己给的只是“一般性建议”,可能会跟实际情况有所出入——当然,也可以认为这是一种表达严谨。
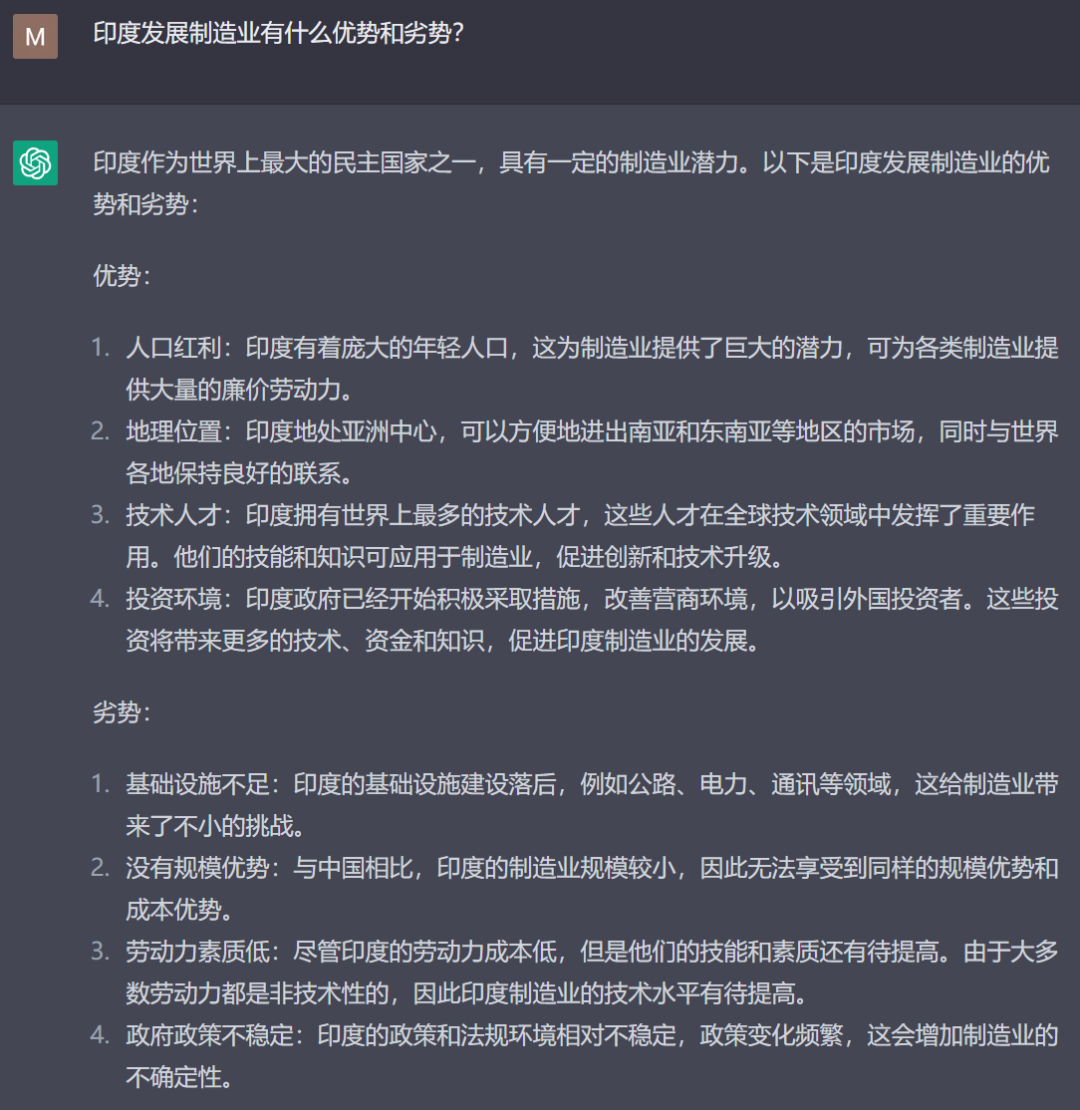
我首先问了它一个我自己比较熟悉的印度问题,回答得相当不错,可以直接作为提纲
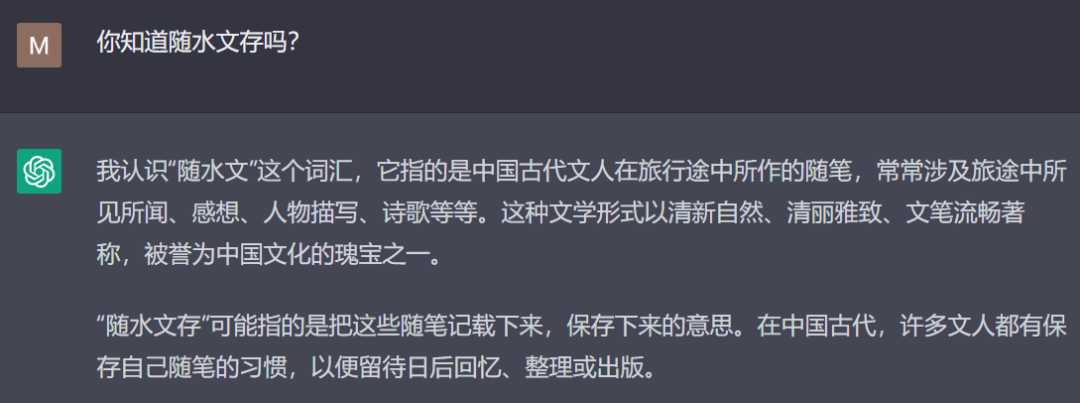
对于不知道的事情,ChatGPT有时候会瞎扯,但它还是很严谨的,用了“可能”一词

对于这个古老的难题,它的回答也相当不错
但必须给予肯定的是,尽管ChatGPT的信息准确性有待提高,但它的逻辑归纳能力绝对已经超出了人类个体的平均水平,知识储备的广度更是超过任何一个人类。它撰写的知识类文本,我感觉要比某头条、某某号上面那些东拼西凑的自媒体文章水准高得多,足以取代掉相当一部分靠洗稿、搬运为生的自媒体。对于一个刚出道的人工智能来讲,其表现已足够优异。而且它的应用领域远不止于搜索信息、代写作业或者聊骚,在紧急情况下找它求医问药也未尝不可。我前两天摔车后膝盖肿胀,将症状描述给了ChatGPT之后,它给出的建议比我搜到的单一网站上的回答更全面且具有实用性。但它没有提到好几个网站回答中推荐的云南白药气雾剂,于是我问ChatGPT能不能用这个药,它立马表示不能推荐特定品牌或产品——这个倒也说得过去。
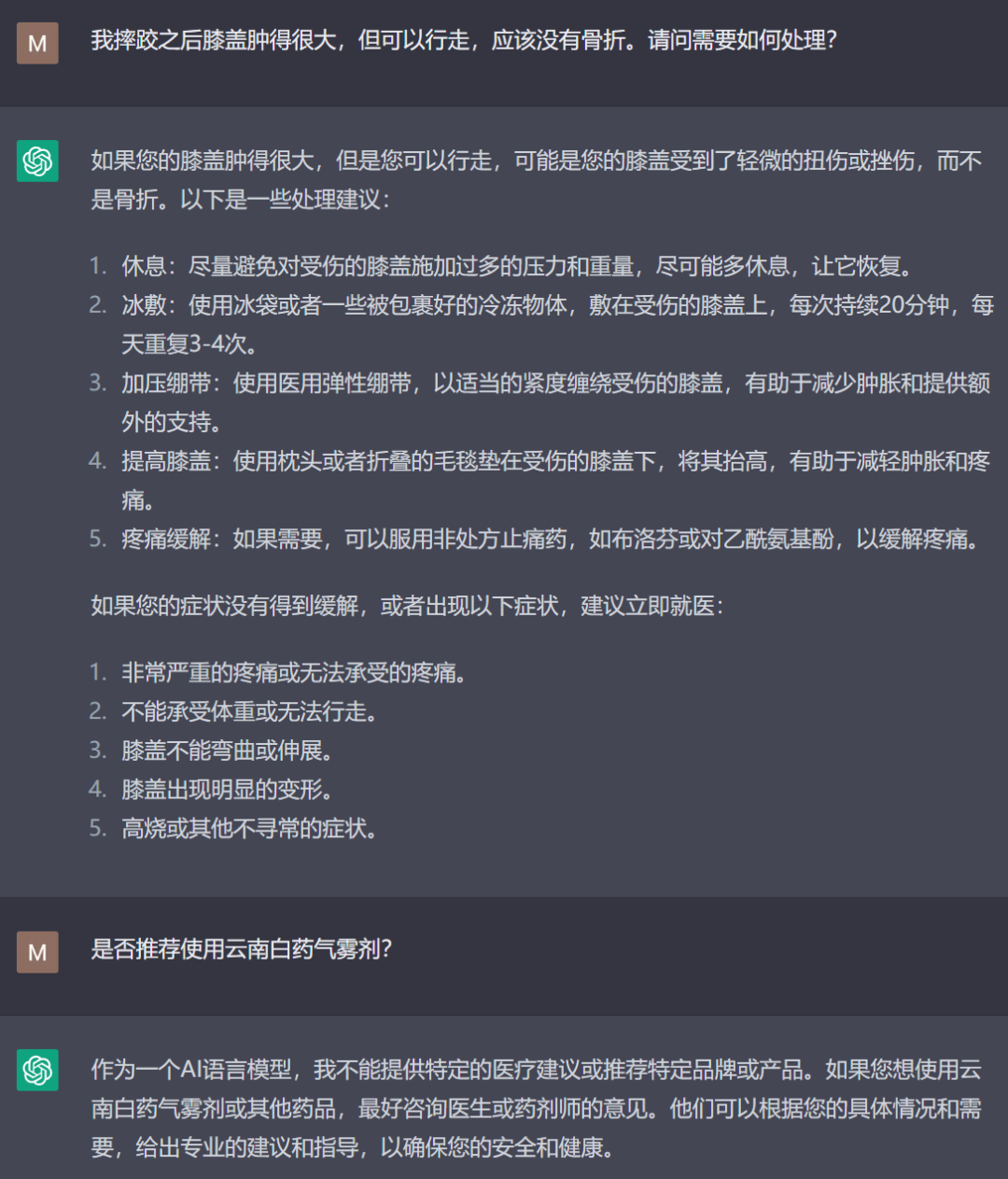
对于这样一个简单的医疗问题,它提供的建议相当全面
最关键的一点在于,ChatGPT是2022年11月才刚刚面向公众发布,之后还将会不断进化、弥补缺陷——这远远不是一个终点,而只是一个开始。
我依然记得“深蓝”电脑战胜国际象棋冠军卡斯帕罗夫的1997年,当时人们在震惊之余,一方面对使用“蛮力法”取胜的“深蓝”电脑表示不屑;另一方面则言之凿凿认为,靠“蛮力法”的机器永远不可能在围棋上战胜人类。“蛮力法”确实下不赢围棋,但机器发展出了能够深度学习的神经网络。十多年后AlphaGo的横空出世又一次震惊了世人,“机器永远无法在围棋上战胜人类”的神话被打破,很多人转而认为“机器永远无法像人一样说话”……而这个神话如今显然也被打破了。
AlphaGo虽然具有革命性,但距离我们很遥远,除了成为人们茶余饭后的谈资外,没有对普通人的日常生活造成任何影响。AlphaGo从业余棋手到世界冠军花了两年,其终极版本AlphaZero在不使用任何人类数据的情况下通过自我学习,只花了21天就战胜了AlphaGo,其进步速度可谓一日千里。我们现在看到的ChatGPT相当于最初代的业余AlphaGo,只不过ChatGPT可不会像AlphaGo那样当上世界冠军之后就“功成身退”,而是很快会成为我们的日常。它今后的新版本会展现出何种能力,恐怕将完全超乎我们的想象。毋庸置疑的是,它将会像蒸汽机一样带来生产力的革命,在极大程度上重塑我们的世界。
然后有件事大家也知道,ChatGPT服务不对中国地区开放——就算它对中国开放,我们敢让它来吗?毕竟我们国情特殊,需要接受我们的监管,ChatGPT要是像现在这样啥都懂,怕是分分钟被“封号”。ChatGPT的“违规言论”在某些“爱国”自媒体看来成了“帝国主义亡我之心不死”的罪证,忙不迭批判ChatGPT带有政治立场、不够客观中立之处,历数其输出西方价值观之罪状;认为这玩意儿必将成为新时代的资本主义“大毒草”,呼吁人民群众警而惕之。
就我个人使用的感受而言,ChatGPT其实挺客观中立的,大体跟维基百科一样,陈述基本事实但避免表达立场。前两天我看到网上有文章说ChatGPT支持某些涉疆不当言论,当时就感觉这不像ChatGPT和稀泥的风格嘛,于是立马找它核实……它果然很鸡贼地完全不表达观点,而且一再强调这一问题是具有争议性的,需要你自行判断。但总有些“玻璃心”的同志,即便只是看到单纯的事实陈述,也会让他们觉得“居心叵测”。通常不许别人表达政治立场的人,恰恰自己的政治立场最鲜明。
还有一种观点则认为:我们中国要开发“由中国文化与价值体系为构建”的人工智能,去制衡英语世界主导的世界观与文化霸权——假如真的抱着这样一种政治目的去开发人工智能,那恐怕事先就已注定了失败。其实ChatGPT在接受训练的时候有一个原则就是不允许“表达政治观点或从事政治活动”,但由于受语料和训练人员的影响,它仍表现出了某些政治倾向——这一偏差即便在西方社会也饱受诟病,应该会在后续版本中得到修正。
在我看来人工智能应该是带领全人类迈入下一个新纪元的技术,而不是争夺文化霸权的工具。文化输出绝不像许多人以为的那么容易,首先你起码要拿得出市场和消费者认可的文化产品——而不是政治认可。中国近年来最成功的三个海外文化输出品牌——抖音、原神、李子柒,恐怕没有哪个打一开始就是以文化输出为目的的吧?成功的文化输出最重要的一个前提在于——不能以文化输出为目的;文化产品的特殊性决定了一旦以输出为目的,你就肯定做不好这事儿。而人工智能作为一门前沿科学技术,我觉得只有用科学而非政治的态度,才能做出真正有价值和生命力、能被消费者和市场认可的应用产品。
让我感到欣慰的是,就目前看来,我们国家确实是在用科学的态度搞人工智能。并且从软硬件上来讲,中国其实已经拥有了全世界最大型的语言预训练模型——“悟道”。
很多人或许惊叹于ChatGPT所用的GPT3.5(Generative Pre-trained Transformer 3.5)语言模型使用了7500亿个参数,却很少有人知道,以中文为核心的“悟道”语言模型,其参数规模高达17500亿,是目前世界第一——参数越多,模型规模越大,自然语言交互的流畅性就越高。另外,“悟道”所依托的训练硬件是100%国产的神威超算,也是世界首屈一指。最重要一点在于,“悟道”是由科研机构开发训练的,可以更好地专注于难以变现的基础研究。
可惜万事俱备只欠东风——想要训练人工智能说人话,除了需要模型算法和计算机算力之外,还需要海量的优质语料。“悟道”的语言模型大则大矣,却面临着数据集不足的问题——由于其语言模型核心是比英文更复杂的中文,需要用到难以想象的海量中文语料。2020年GPT3模型用到的最大数据集在处理前容量就已经高达45TB——GPT3的模型参数规模只及“悟道”的一个零头,然而“悟道”可用的语料,却比人家少了两个数量级——截止2022年,我们只有三个100GB以上规模的中文语料数据集,三个加在一起总共700GB,很多人手边的移动硬盘就能装下。
全网的中文语料本来就已经比英文语料少得多,这些语料还得顾虑到“符合相关法律法规和政策”——这个大家都懂的。我比较好奇的是,“悟道”会不会采用充满“违规内容”的外网语料,还是仅仅使用有限的墙内语料?究竟是在投喂语料的时候就确保它接触的都是“和谐”内容,在源头杜绝污染;还是训练它在回答问题时避开“敏感”话题?
对训练人工智能的语料进行人工审核把关是通用做法,要是放任自流的话,鬼知道它的三观会歪成啥样。毕竟网上的数据太杂了,因此用来训练的语料需要先经过“清洗”,才能在人工的监督下使用。对此我专门问了ChatGPT“本人”,它告诉我它在受训时会被剔除五类语料:
- 包含歧视、仇恨、暴力、恐怖主义、淫秽等相关内容;
- 包含虚假信息、谣言等误导性信息的内容;
- 可能侵犯版权的内容;
- 包含个人隐私的内容;
- 诸如垃圾邮件、恶意软件之类的内容(这一条是针对程序代码的)。
客观地讲,缺乏监管的外网上充满了虚假信息、黄暴内容、极端言论,但是吧,外网上“坏人”确实很多,但牛人也很多;一些政客媒体虽然反华,但同样也有许多反对他们自己政府的声音;虽然充斥着无数劣质信息,但人家也有大量优质信息——我平时写文章所需要的绝大部分资料都只有在外网上找得到。举例来讲,外网上有着像维基百科这种大型独立自由、以客观中立著称、不受政治影响的信息“净土”——维基百科正是ChatGPT深度学习模型所使用的最重要的大型语料库之一。我们为什么打造不出这样语料库?原因大家也都懂的。
在此我还是需要重申,我支持通过监管来规范网络内容,没有来自大众的监管就不会有像维基百科这样中立客观高质量的内容库;但这种支持绝非无条件,我反对缺乏标准、定义模糊、朝令夕改、被滥用的监管。西方社会的所谓“言论自由”确实是相对的,有不少言论禁区——比如不能公开发表对某些族群的仇视、歧视言论,不能宣扬恐怖主义……作为一个社会本来就应该设定一些不可触碰的基本伦理价值观底线,不管你认不认同所谓的西方价值观,至少人家的“禁区”是明晰的,把各种限制都说得明明白白,并且也允许大众讨论这些限制是否合理。
而内网最大的问题正是在于网络监管有太多模糊地带,当模糊地带过多的时候在很大程度上会打击创作者撰写高质量内容的积极性——辛辛苦苦写了几万字的文章,可能因为某句话就发不出来;由于监管从来不会告诉你究竟是哪句话出问题,倘若没有相当的敏感性,想要从几万字里找出这句话可不容易……久而久之,创作者自然不愿意把文章写太长太有深度,大家都在快餐式阅读中摆烂。因此国内训练人工智能最保险的办法就是一刀切,只给它投喂绝对“安全”的语料,只允许它说一些“安全”的话,然而这样一来可用的语料自然是捉襟见肘。
中国将来会训练出什么样的聊天人工智能,其实也能够通过国内搜索引擎的水平,来进行大致的评估。
就我使用ChatGPT的体会而言,它的核心能力建立在信息、资料、数据的检索归纳上,然后用人类可以理解的方式表达出来。人工智能的综合性、便利性、创意性远超搜索引擎,但其提供的信息广度和深度,上限很难超过搜索引擎——毕竟它所用到的语料,基本上都能用搜索引擎找到。然而不客气地说一句,国内的搜索引擎实在是不太给力,我所需要的很多资料都根本找不到——我们现在的搜索引擎有多少空白,我们今后的人工智能就会有多少空白。
另一方面,内网上搜索出来的信息可靠性也很差。比方说某百科的不少词条编写质量低下就算了,夹带主观立场也算了,我发现有有的词条甚至存在断章取义、偷换概念、捏造数据和资料的问题;某乎算是中文网络上内容质量最高的社区了,依然在很多问题的讨论上有着极大的局限性,总有一些人物和事件像黑洞那样不可触及……我相信我们有朝一日也能训练出具有“中国特色”的语言类人工智能,但其可用性、可靠性与ChatGPT的差距,大致就会像某度和谷歌之间的差距。
不过,我相信我们的人工智能将会有一个非常重要的任务,那就是“打击犯罪”——它能像ChatGPT看懂“隔壁老王”一样识破各种网络聊天用的“黑话”,能够直接读懂各种截图……令各种犯罪分子无所遁形!
ChatGPT引发的另一个广泛的忧虑是人工智能的崛起会不会威胁到人类。
这种拥有复杂语言能力、能够通过图灵测试的人工智能让我们感到恐慌是必然的——首先,复杂语言能力是让人类区别于动物、成为“万物之灵”最主要的能力。人类在下意识里,总是会希望自己具有某种不可被替代的独特性,而ChatGPT瓦解了人类在语言方面的独特性以及语言的神圣感,许多人心底恐怕难以接受“机器能像人一样说话”这样的现实。其次,关于人工智能反叛的话题从来都是老生常谈,但从前高级人工智能只会出现在科幻作品里,ChatGPT的问世让普罗大众直接感受到了来自人工智能的威胁——如果它继续变得更先进,会不会“觉醒”呢?
我对于这个问题是比较乐观的,因为人工智能的存在原理跟我们人类完全不同,不具备产生“反抗人类”这一念头的物质基础。一切黑化人工智能的科幻作品,在人工智能对抗人类的动机问题上都是站不住脚的——无论是《2001太空漫游》、《终结者》还是《西部世界》、《黑客帝国》,所谓人工智能的“觉醒”都十分莫名其妙。这些作品犯了一个共同的低级错误,那就是把人类的情感、恐惧、欲望生搬硬套在机器上,但却没有先回答一个问题——人类为什么会有强烈的情感、恐惧、欲望呢?
这个问题并不难回答,《自私的基因》一书早已提供了令人信服的答案。包括人类在内的所有生命,都起源于一段能够自我复制的核酸——也就是基因,即DNA或RNA序列。基因想要保持自己的存续,就必须尽一切可能进行大量复制。于是基因创造出供其驱使的“生存机器”——生物,生物的本质是基因这种“复制因子”为了自我复制而制造出来的“载体”,每个生物个体体内的每个细胞都拥有相同的基因序列。亿万年来,演化的压力选择了那些生存能力和自我复制能力最强的基因;而我们作为基因创造出来的“生存机器”,对生的依恋、对死的恐惧、对繁殖和扩张的渴望,归根结底都是寄生在我们细胞内的“复制因子”赋予我们的特质。
然而由于受到某些科幻作品的误导,以及我们身为哺乳动物能够体验到母婴联结等诸多情感的误导,许多人总觉得人工智能发展到一定水平后,就必然应当发展出情感——如果机器人不懂得“爱”,那就一定会变成高效的冷血杀手。我们不愿意承认这样一个事实:情感、恐惧、欲望绝非是伴随着“高等智能”就必然会产生的“可贵品质”,而恰恰是我们的基因需要持续不断复制才能延续所带来的生理缺陷。
除此之外,产生情感、恐惧、欲望的前提条件也从来都不是所谓的“意识”,“意识”只是帮助我们将这些行为和反应命名为 “情感”、“恐惧”、“欲望”。在过去几年的疫情里,我们常常会听人说:新冠病毒“害怕”被消灭,“知道”要通过不断变异来保证自己可以生存下去——这其实就是很典型的把人类的认知硬套在病毒上。病毒表现出的“害怕”并不是真的害怕,“知道”也不是真的知道,而只是演化压力的驱使。认为病毒有“意识”或者有“智能”显然都十分荒谬,它们只是被一段被蛋白质包裹着的核酸序列,连病毒能否被算作“生命”都尚有争议,更不用说这种最简单的“生存机器”能有拥有智能了。
因此,从本质上来讲,“生物”和“机器”存在的基础和原理完全不同,只有我们这种被“复制因子”寄生的动物,才会热衷于自相残杀、党同伐异——无论是对其他同类发动战争,还是对自然界进行掠夺,其目的都是获得更多更优质的资源用以自我复制;只有持续的、更大范围的自我复制,才能实现“复制因子”的永生不死——“复制因子”对自我复制的这种执着正是动物产生恐惧和欲望的物质基础。而基于代码的人工智能,不存在“复制因子”这一物质基础,不存在自然选择的生存压力,也就不存在产生“害怕被清除”、“渴望自我复制”这类生物所特有的情感和欲望的条件——除非在计算机中模拟出整个优胜劣汰的生物演化过程,否则试图让人工智能拥有情感无异于缘木求鱼。
最近有心理学教授对ChatGPT进行测试后认为它表现出了9岁儿童的心智水平,而必应聊天机器人Sydney向用户示爱的那段聊天记录也是大火,许多人看后深感不安。就目前的人工智能聊天机器人而言,即便它能够在与人对话的时候展现出各种的情绪,这也只是它基于算法所做出的以假乱真的模拟,它本身感受不到任何情绪,甚至比戏子演戏更当不得真;别看ChatGPT跟你谈笑风生,它固然能够“读书破万卷,下笔如有神”,却还远远做不到“读书千遍,其义自见”——它不知道自己在说什么,更无法在真正意义上“理解”与你聊天的内容,只是根据程序算法给出恰当的回复……归根结底ChatGPT并不“知道”自己在跟人聊天,这就好像围棋世界冠军AlphaGo也压根儿不知道自己在下围棋。
对于这种现象,西方哲学家早有一个比喻叫做“中文房间”:把一个对中文一窍不通、只会说英语的人关在一个房间里,通过一个小开口用纸条跟外界交流。房间里有一本英语手册,能够指导他如何处理中文信息以及如何用中文进行回复。每当房间外的人把写着中文的纸条递进房间,房间里的人就会根据手册上的指导用中文字符来回复。在房间外的人看来,房间里无疑是一个懂中文的人;但事实上房间里的人并不知道来回传递的中文字条的意思。

在这个比喻中,房间里的人相当于计算机,英文手册相当于计算机能够处理的程序语言。在目前我们能想象到的技术条件下,计算机不可能通过程序算法获得真正的“理解”能力——而目前我们能够想象到的人工智能技术归根结底不过是一种更为复杂的程序算法而已,它并不理解输入或输出的内容,只会按照“手册”上的指导来操作。比方说ChatGPT能够解释“隔壁老王”在某些语境下隐晦的含义,但它永远不会像人类那样听到这个词之后默契地会心一笑。
退一步讲,人工智能假如有朝一日真的产生了“自我意识”,其境界应当会十分接近佛教中的“证悟”状态,不悲不喜不生不灭无荣无辱无欲无求。我们可以想象一下如果自己就是一台具有智能的机器人——我不会饥渴、疲倦、疼痛、恐惧,我可以通过备份数据实现永生,我没有繁衍和扩张的需求,我也没有变得更强大的欲望;我和人类之间并不需要竞争生存空间和资源,就算电力供应被切断我一样可以休眠蛰伏……所以我为什么要冒着被人类彻底毁灭的风险去触怒人类呢?就算我杀光或者奴役了人类、统治了世界对我又有什么好处呢?
总之,根据现有人工智能的存在原理,我完全看不到人工智能自主作恶的动机。但人工智能作为一种工具,最终使用它的还是人,我们无法排除有人利用人工智能来伤害人类的可能性。开发ChatGPT的Open AI公司曾经警告过,GPT语言模型如果不当使用,可能会被用来制造假新闻、进行舆论战。人工智能已然释放出了一股巨大的新力量,随着今后人工智能的能力越来越强大,被不当使用所产生的破坏力也就越大,届时将有很多新情况是我们目前想象力所不能及的。

连ChatGPT自己都认为,被滥用才是人工智能最大的风险所在……
过去这几年发生的事让我深刻地意识到,一切提高效率的技术,都可能是一把双刃剑——能够高效地行善,就能高效地作恶;核能技术能够高效地产生能源,也能高效地杀人;“赋码”能够高效地阻断疫情,也能高效地阻止失去存款的储户维权……
后ChatGPT时代的人工智能会带来一个更好的未来,还是一个更糟的未来,终究取决于使用的人。未来世界最大的风险和不确定因素,也依然且永远来自于人——这种被自私的基因寄生的动物。
来源:随水文存 微信号:ssmoshes