
@卢诗翰:今天聊下#GPT4# ,我的观点是:chatgpt等AI产品并没有单纯的消灭工作,而是取代一部分也创造了一部分,只是创造出的这部分,并不在大众视线范围内。
例如——拉框
1
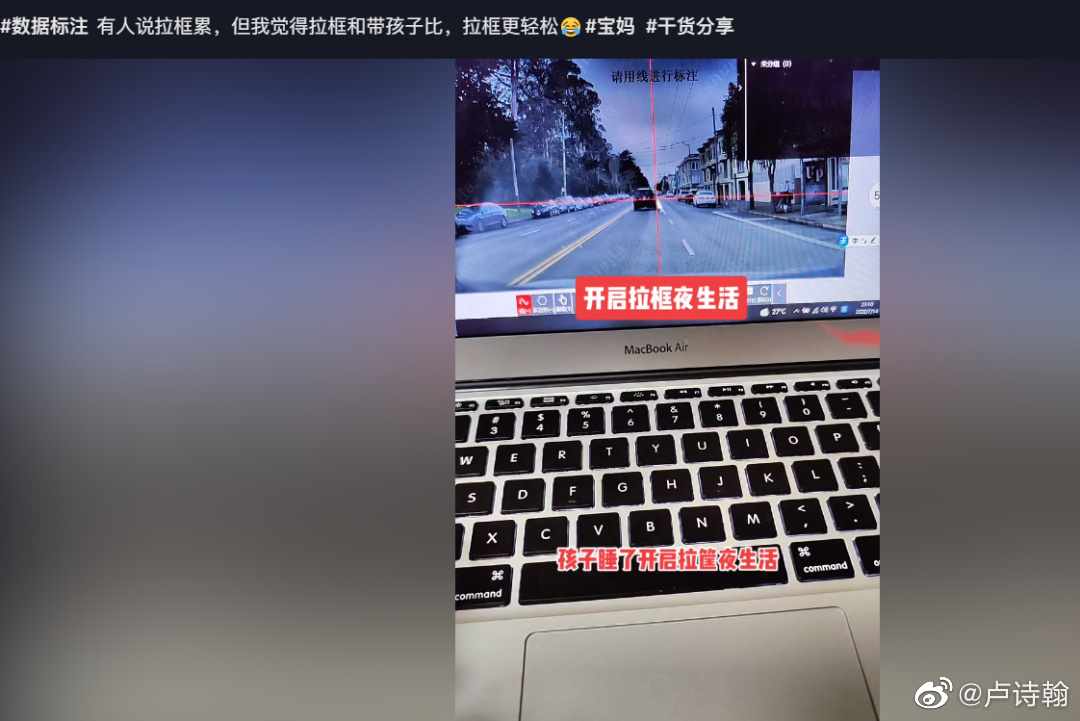
什么叫拉框呢?像图一这样对图片中的汽车进行数据标注就是,因为刚好是用鼠标拉一个框,所以俗称拉框。
熟练工一天能拉完5000个框,一个框0.02元,一个月下来会有3000的收入。
看起来并不高,但问题在于,这个工作,不分地域,不分场所,待在家里一台电脑就能开工。所以很多宝妈,在家休息时就可以干这个。
那有人可能问了,你说这个拉框,和今天要聊的chatgpt有什么关系呢?
关系就是,chatgpt背后,就藏着无数的拉框工作者。
2 chatgpt的本质
chatgpt出来的时候有许多人提问,为什么国内没有类似的产品。
实际上是有的,比如之前我说过的阿里鲁班,他们也可以用AI去自动绘图,速度也很快。
但是,为什么国内这些产品给大家的颠覆性没那么强呢?因为很多产品的界面是图二这样的:
懂行的人可能会觉得,这个界面已经非常简洁了啊,相比PS等设计软件,没有图层蒙版一堆功能,你就把标题写好字体选好颜色选好,只要三个参数,一分钟都不用,然后AI就能帮你生成图片了,这还不够简单吗?很智能了啊。
可问题在于,chatgpt的界面是这样的
发现区别没有?
chatgpt的巨大进步在于,他能理解你在表达什么。不需要参数设置界面,直接输文字就行。别的软件你需要选择“标题黑色-宋体-5号字,正文黑色楷体4号字”
而chatgpt这里只需要说,“给我的论文排版”
前者需要懂一点基础知识,后者哪怕是小学生都可以,这就是差异所在。
为什么chatgpt能如此智能的理解你在表达什么呢?
一方面,是算法的进化,逻辑的进化,另一方面就是素材的积累,更多的学习素材,更精确高质量的学习素材。
而学习素材,就是靠无数拉框人拉出来的。
3 拉框史
2007 年,计算机视觉专家李飞飞在图像识别项目中,雇佣了一群普林斯顿的本科生,以 10 美元/小时的价格让他们以人工的方式寻找照片并添加进数据集。
很快,她发现这样做效率低,成本也大。
随后有人和她说起了亚马逊的众包平台 Mechanical Turk,他们就想到可以用这个平台来低价雇佣全世界的人为数据做标注。之后有人发现,他们的算法在使用了李飞飞这个更大更精确的“学习资料库”训练后表现的更好了。
2012年,Google的吴恩达和Jef Dean训练了一个当时世界上最大的人工神经网络,用来教AI绘制猫脸图片。训练数据来自youtube的1000万个猫脸图片,1.6万个CPU整整训练了3天。
2016年3月,Google的AlphaGo战胜围棋世界冠军李世石。
2018年6月OpenAI发布了第一版的 GPT-1。具有1.17个参数,使用了5GB的无标注文本数据,在8个GPU上训练了一个月,然后再进行人工监督的微调。
2019年2月GPT-2发布,使用40GB文本数据训练,参数量突破到了15亿。
2020年5月GPT-3发布,使用了45TB文本数据训练,有1750亿参数。
不少人的看法是:只有参数达到千亿以上的大模型才可能拥有强大的思维链能力,而这只是必要条件:有些千亿参数大模型没能展现出思维链能力。
4 训练
理解了这些,你差不多就能理解chatgpt们的逻辑了,
比如人像,什么是人像呢?你需要用无数张照片喂给AI,就像教小孩子一样告诉他,这个框框里的就是人。
所以拉出的框框要精确,越精确质量越高,AI学习的越好。
同理,车辆框,甚至文字也一样
再比如句子,以“今天凌晨苹果公司发布了iPhone14”一句为例,该句中一共有“今天、凌晨、苹果、公司、发布、了、iPhone、14”八个需要标注的词性以及依存句法,其中今天为时间词,标注为t,该短语又属于定中关系,需标注为ATT;凌晨同样属于时间词,标注为t,但在句法上属于状中结构需标注为ADV。
所以,一个有意思的情况是,目前大众眼里无所不能的AI,在这些标注员眼里却是另一面
——“人工智能也没那么神奇,多少人把几百万、几千万的句子掰开揉碎了教它才教明白,教人才没这么费劲。”
总而言之,你喂给AI的案例越多,喂的时候标注的越精确,他越聪明。超过一定级别后,AI识别能力更是会有突飞猛进的增长。
当然,很多时候也不是你喂给他,而是他做出题目你去审,人工再去对AI的判断结果做一次对错判断。往AI里输入的叫数据标注,给AI对错纠正的叫数据清洗。
5 岗位
而由于需求旺盛,目前各大招聘网站已经有大量这类岗位的招聘。甚至在大量咨询下,还涌现了不少骗子公司。
很多岗位你会发现并非在一线城市,甚至在三四线。
这些岗位的薪水并不高,但靠着三四线生活成本低又不用背井离乡的优势,往往能轻松招到很多人。
我之前介绍过的阿里的“AI豆计划”就是这个赛道。他们在吕梁山区已经初步形成数字就业产业带,带动600多名当地人就业,许多都是之前难以找到工作的留守女性宝妈们。永和县的一家标注公司在风口下快速发展,2022年所有员工平均月薪甚至超过了4000元。
(还是那句话,别单看金额,还要看地域,当地原本是贫困县,这个算高收入)
当然,有类似操作的不止中国公司,比如chatgpt,他们没找中国三四线县城工作人员来标注,他们找到的是非洲肯尼亚的工人们来进行数据标注。开出的时薪是2美元,在硅谷这是不可能找到人的价格,但在当地一样是争破头的香饽饽。
亚马逊等也一样,2022 年 11 月,The Verge 报道亚马逊在印度和哥斯达黎加聘请了工人负责观看仓库摄像机数以千计的视频,从而改进亚马逊的计算机视觉系统。
所以很多人说中国有廉价劳动力优势,不应该做不过欧美企业的时候,我必须得说一句
老牌帝国主义们在寻找全球劳动力洼地上,那也是经验丰富敢想敢做的。
你觉得硅谷纽约人力成本高,但人家会满世界找便宜劳动力。
用AI圈里一句话来说:人工智能,有多少智能,就有多少人工
6 不是取代,而是变迁
明白了这些,你可能对于许多事会有新的看法。
比如前两天我看见不少人说,AI淘汰画师淘汰设计师,是计算机取代人类。
但其实真正情况是,并不是简单的计算机取代人类
而是,三线城市月薪4000的标注员x10+一线大厂月薪50000的算法人员》月薪20000的画师X10。
工作人数可能并没有变化,只是群体从一二线画师变成了三四线人员。
很多岗位在KPI,OKR等制度的分割下,非常专一化,比如老一代广告公司会有AE等专门和客户打交道的岗位。而新一代画师设计师可能压根不接触甲方,就专注从平台上接单子。
这样的步骤分割非常垂直的模式,和标注员+chatgpt这套模式非常像,我认为这样的岗位就是最容易被AI+标注员取代的。
只是目前三四线月薪4000的标注员们声音不大,大众关注也不多,所以大家光看到AI在消减岗位,没注意到AI也创造了很多新兴岗位。
就像当年火车淘汰马车一样,大家都能看到马车夫的岗位被取代了,但很少有人意识到,火车本身带来的新兴岗位,其产业和拉动的就业同样是一个庞大的数字。1804时的人们,很难去想象“铁道兵”“锅炉员”“高铁空姐”等事物。
唯有变化,才是永恒不变的
参考资料:
一文读懂:AGI的进化编年史
那些在人工智能背后打工的人
百度华为阿里腾讯都要搞ChatGPT,认真的吗?
信息麦田里的数据农民
给AI当老师,比教人还费劲
 微信扫一扫打赏
微信扫一扫打赏 支付宝扫一扫打赏
支付宝扫一扫打赏:format(webp):quality(80)/https://img.bohaishibei.com/2025/06/23/xqDiofaBjrS7KJs.webp)
:format(webp):quality(80)/https://img.bohaishibei.com/2025/06/23/YHEfdxJIkrqU3bi.png)
:format(webp):quality(80)/https://img.bohaishibei.com/2025/06/23/eN6JiPoqyDlhbSd.png)
:format(webp):quality(80)/https://img.bohaishibei.com/2025/06/23/OUprogVZhcQAPRF.jpg)
:format(webp):quality(80)/https://img.bohaishibei.com/2025/06/23/EAJlgVLHs2aiRCM.jpg)
:format(webp):quality(80)/https://img.bohaishibei.com/2025/06/23/lUn4Mqe5HLd9stv.jpg)
