


最近 4 个月,整个世界因 ChatGPT 进入快进状态。几乎每隔几周,最近是每隔几天,就有人工智能新进展刷新新闻版面,也刷新人们的认知。
面对 ChatGPT 和背后的大模型机会,中国科技大公司的共性是,一把手亲自跟进。
字节跳动创始人张一鸣开始看人工智能论文了。一位字节人士称,张一鸣近期时常会和一些字节人士分享论文学习心得和对 ChatGPT 的思考。他在两年前已卸任字节跳动全球 CEO,但依然是字节重大战略的筹谋者。
阿里巴巴董事局主席兼 CEO 张勇忙着对阿里做大重组,但也亲自盯阿里的人工智能新项目,阿里将在 4 月 11 日举行的云峰会上发布大模型进展。
在百度开始文心一言内测前,百度创始人兼 CEO 李彦宏每晚和项目团队开会,他们为筹备产品甚至一度睡在公司。
腾讯和华为管理层也公开表达了对大模型的重视。3 月底,腾讯总裁刘炽平在财报电话会上说,生成式人工智能可成为腾讯已有业务,如社交、游戏的 “倍增器”,也可帮助开拓数字助手、搜索等新增长线;腾讯正在加速推进大模型 “混元”。
华为创始人任正非 3 月中旬参加华为 “难题揭榜火花奖” 颁奖座谈会时称,华为会做底层算力平台:“未来 AI 大模型会风起云涌,不只微软一家。ChatGPT 把计算、管道流量撑大,华为的产品就有了机会。”
中国互联网和科技行业,很久没有像这样同时瞄准一个目标了。即使是疫情前各公司密集进入,押注重金的社区团购买菜业务,也没有如今的景象。
除上述最被关注的公司外,从 GLUE(通用语言理解测评)、 CLUE(中文语言理解测评)榜单看,快手、美团、京东等互联网公司,科大讯飞、商汤等人工智能公司,和 OPPO、vivo 等智能硬件公司也都发布了自己的大模型。
没有犹豫的时间,共识很快达成。与过去更多处理特定任务的人工智能不同,以大模型为基础的人工智能要通用得多,它既可以帮你列出采访马斯克的问题,也能给出一份能源市场分析框架,仅靠简单的语言描述,它就能生成一幅奇幻风景或 logo 设计草图,甚至是动态视频。
在前沿技术的跨国流通不再那么通畅的今天,中国市场需要自己的大模型。能提供本土最好大模型的公司,会获得极高商业回报。这一新技术可能很大程度改变人们获取信息(搜索)、与人互动(社交)、创造内容(游戏、短视频、知识工作等)的方式与效率。
OpenAI 并未公布过训练 GPT 系列模型的成本,据估算,即使是三年前训练 GPT-3 时,花费也高达上千万美元。大公司更有资源跟进这一高门槛方向,但他们也需要解决一连串大公司转身时的挑战,其中很多不仅关于技术。
一个共识:同时做模型层和产品层
已相对清晰的是,多数中国大公司都在同时做大模型和基于模型的应用。这是在跟随 OpenAI 的实践。
ChatGPT 本身是一个应用层产品,它背后是 OpenAI 自 2018 年陆续推出的 GPT(Generative Pre-trained Transformer)生成式语言大模型系列。后者是前者的技术底座和能力支撑,前者为后者持续提供用户反馈与新数据。二者构成一个循环飞轮。
具体应用方向上,综合公开报道和我们了解的信息。字节将在抖音、TikTok 搜索和图片 / 视频生成方向发力。字节可能会在抖音、TikTok 中推出类似微软问答搜索引擎 New Bing 的功能。图片 / 视频生成则主要服务字节商业化需求,以帮助字节广告客户更方便、低成本地制作视频。一位字节人士称,字节广告客户投放总成本里有 10%-20% 为视频制作成本,从去年开始,字节已在开发一些相关产品帮广告客户压缩这部分投入。
去年 6 月腾讯发布混元大模型时称,混元已被用来理解广告内容,以帮助更精准地把广告投放给特定人群,该模型也已在向广告主提供图像、视频生成能力。微信搜一搜功能今年也已应用了混元大模型,让搜索结果的相关性排序变得更准确。
微信去年 10 月也推出了数百亿参数的通用语言大模型 WeLM,有续写故事、翻译、扮演角色的能力,比如你可以通过 WeLM 问马斯克,收购了 Twitter 后他准备怎么干。
阿里可能会结合云、电商场景,推出基于大模型的一些新服务或功能。大模型与云的结合思路与百度类似。电商的以文搜图找产品、精准推荐、数字人直播、店铺广告物料生成和产品内容生成等流程上都有大模型和生成式 AI 技术的用武之地。阿里智能音箱天猫精灵近期也在做技术测试,接入了大模型能力以实现更好的多轮对话效果。
阿里还在研发类似 ChatGPT 的对话机器人产品形态,3 月底已对员工开放内测。一名参加测试的阿里人士称,它的运算能力还比较差,会算错个位数加减乘除,整理周报时会自己生成几条原周报里没写的事。据了解,下周举行的阿里云峰会上可能会公布相关进展,该产品不会直接 to C,测试对话形态主要是为了让企业客户体验产品能力。
百度的大模型目前的内部应用方向有搜索、云服务、小度智能音箱和智能交通 / 自动驾驶等。搜索产品形态可能也类似 New Bing;百度智能云预计未来会开放大模型 API 接口,以帮助合作伙伴搭建具体应用,或直接提供一些打包好的 SaaS 产品;在智能交通上,百度地图本周推出的新版本中已嵌入了文心大模型能力,百度称新版本可优化交通调度效率,还能让地图更好地理解用户发出的指示,节省沟通时间。
阿里和百度都已在建设大模型生态,即以云平台输出模型能力,支撑更多应用生长。阿里在去年的云栖大会上提出了 MaaS(模型即服务,Models as a Service),李彦宏在半个月前发布文心一言时也提及了这一概念。阿里去年 11 月初推出模型社区 “魔搭”,上线时汇集了达摩院的 300 多个开源模型。百度在其深度学习框架飞桨平台中设置了供开发者调用的 “模型库”。
字节跳动:今年初组建团队,横跨多国、多部门
沿着 OpenAI 蹚出的路,同时做模型和应用的中国各科技公司均拉出了多部门协作阵容:由有资深人工智能背景的技术高管领头模型层开发,同时调集产品团队支持基于模型的应用。
字节今年初才开始组建专门的大模型团队。但集结颇为迅速,参与部门众多,国内国外均有分布。
这之前,字节于 2021 年底调整组织架构,分立六个事业部(抖音、大力教育、飞书、火山引擎、游戏和 TikTok);同时保留了独立于业务的中台技术部门,做通用底层技术;另有一些技术团队分流到了不同事业部,汇报给事业部负责人。
据《晚点 LatePost》了解,目前参与字节大模型的技术负责人有朱文佳、项亮、李航等,他们分属字节多个部门。
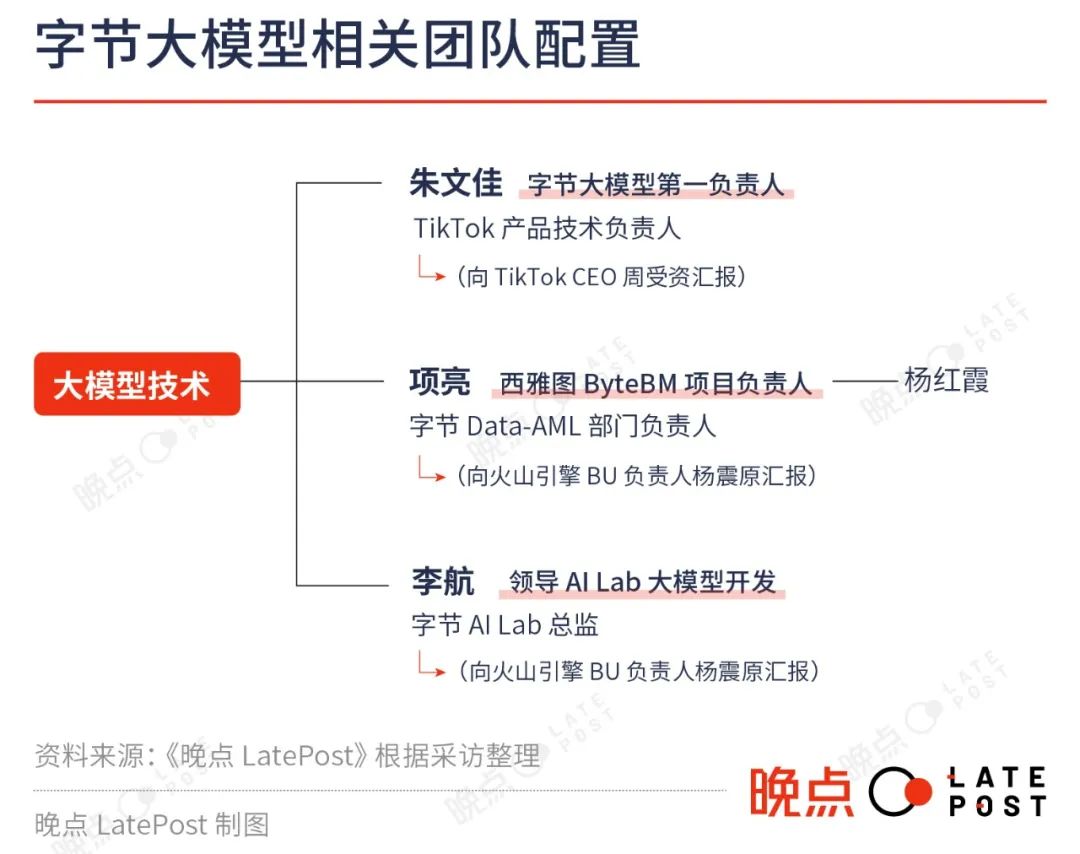
其中朱文佳是字节大模型的第一负责人。他是 TikTok 产品技术负责人,字节搜索部门也向他汇报。字节大模型的主要应用方向之一即是优化抖音或 TikTok 的搜索。
项亮为技术中台下的 Data-AML(数据-应用机器学习) 负责人,他是推荐算法的重要贡献者。AML 近期新成立了一个与大模型有关的项目 ByteBM。去年离开阿里巴巴达摩院,后加入字节跳动的杨红霞即在项亮团队。她曾担任达摩院资深算法专家,是阿里 2021 年发布的多模态大模型 M6 的核心技术人员之一。
李航是字节 AL Lab(人工智能实验室)总监,他曾担任华为诺亚方舟实验室主任和首席科学家,2017 年加入字节,研究方向包括信息检索、自然语言处理、机器学习、数据挖掘等。AI Lab 旗下 NLP(自然语言处理组)组也在参与大模型开发,直接负责人为陈家泽,他 2017 年从北大计算机系硕士毕业后加入字节任算法工程师。
一位字节人士评价,从学术研究到业务落地的光谱上,李航在最左端,中间是项亮,最右是朱文佳,他有 “综合的工程和技术管理经验”。
朱文佳 2015 年加入字节,这之前他在百度担任搜索部主任架构师,研究方向为推荐算法。2019 年,朱成为今日头条 CEO,2021 年 2 月,调任为 TikTok 产品技术负责人。
在产品与应用上,字节在 2019 年推出了巨量创意平台,可以帮广告客户制作视频内容,降低制作门槛和成本,大模型会进一步提升内容生成的质量和效率。该平台隶属字节商业化产品与技术团队,总负责人为刘小兵,他曾任谷歌大脑软件工程技术负责人,2018 年加入字节。
字节参与大模型的团队分布在多个国家,朱文佳的团队在新加坡,项亮团队在美国西雅图,李航领导的 AI Lab 在北京。
大模型是中美两国政府关注的人工智能前沿技术,它的发展也离不开高端计算芯片和海量数据。未来字节将如何安排大模型团队的中美分布和分工还不确定。
百度、阿里、腾讯:首席科学家挂帅,过去数年经历人才流失
百度、阿里、腾讯的大模型团队,均由集团内技术一号位或首席科学家负责。
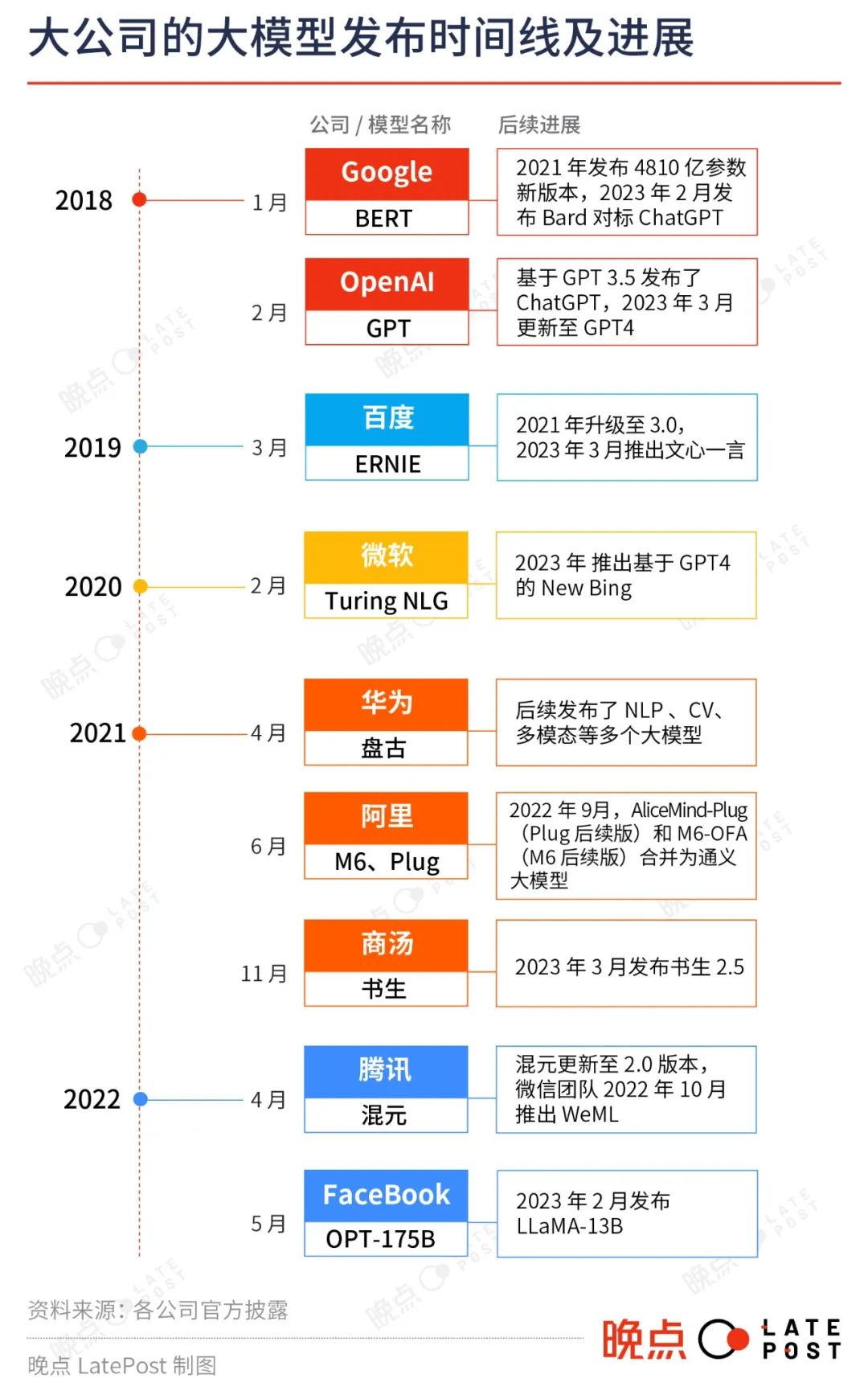
在 ChatGPT 引发的热潮前,这 3 家公司均已发布过大模型:
百度于 2019 年推出 ERNIE 1.0,即后来的文心大模型,目前已更新到 3.0 版本;
阿里于 2021 年连续发布语言大模型 Plug(后更名为 AliceMind)和多模态大模型 M6,去年 9 月,两个大模型合并为阿里通义大模型;
腾讯在 2022 年 6 月发布混元大模型,目前更新至 2.0 版本。腾讯微信团队去年 10 月也发布了大模型 WeML。
综合此前报道和我们了解的信息。百度大模型的开发由百度 CTO 王海峰领衔,他也是文心一言产品的第一负责人。王海峰之下,百度集团副总裁吴甜的团队是开发自然语言处理技术的主要团队。吴甜于 2006 年加入百度,2010 年进入自然语言处理部,2020 年升任副总裁,整体负责百度 AI 技术平台和智能云 AI 产品。
阿里达摩院自 2020 年初开始同时研发多模态大模型和语言大模型,目前阿里的大模型研发仍放在达摩院,负责人为阿里云智能 CTO 周靖人。他毕业于中国科学技术大学,获哥伦比亚大学计算机博士学位,曾任微软前研发合伙人,2016 年加入阿里,任阿里云首席科学家。
具体参与大模型开发的是达摩院 AI 团队,包括当年推出 M6 的达摩院旗下智能计算实验室和推出 AliceMind 的语言技术实验室。其中智能计算实验室主任为周靖人本人,语言实验室现主任为黄非,他向周靖人汇报。黄非毕业于卡耐基梅隆大学计算机学院,2018 年加盟达摩院,曾在 IBM 和 Meta 研发自然语言处理技术。阿里两个实验室目前共有约百名研发人员参与大模型开发。
腾讯则在 2023 年初组建了混元助手项目组。据《36 氪》报道,该项目由腾讯最高级(17 级)研究员、腾讯首席科学家张正友负责,其下有数名产品经理和组长参与,他们来自腾讯不同的事业群,包括技术工程事业群(TEG)、平台与内容事业群(PCG)和云与智慧产业事业群(CSIG)等。跨事业群开发具体产品在腾讯相对少见,这侧面反映了管理层对大模型的重视。
相对独立的微信团队,也开发了自己的大模型,即 WeML。据项目官网,其最新更新日期是去年 10 月。腾讯在大模型上是否也会进行多团队 “赛马” 还不确定。
百度、阿里、腾讯都集结了公司最好的技术力量投入大模型,不过他们过去几年流失了一些重要的人工智能人才。
腾讯大模型负责人张正友专长于机器人,他于 1998 年提出 “张氏标定法”,在机器人控制领域影响深远。他最初加入腾讯时担任机器人实验室 RoboticsX 负责人。大模型则更多与自然语言处理技术有关。
腾讯本有张潼坐镇这一方向,他在 2017 年春加入腾讯担任 AI Lab 主任。张潼是机器学习领域专家,拥有斯坦福大学计算机硕士、博士学位,曾任美国新泽西州立大学终身教授,IBM 研究院研究员和雅虎研究院主任科学家,研究领域包括计算机视觉、语音识别、自然语言处理和机器学习等。
2018 年 12 月,张潼离开腾讯重返学界,加入香港科技大学,张正友接任 AI Lab 主任。2019 年-2021 年,离开腾讯的人工智能专家还有腾讯优图实验室前联合负责人贾佳亚,腾讯原副总裁、AI Lab 创始人姚星等,他们都选择了创业。
阿里达摩院近年也有多位科学家离开。据《晚点 LatePost》了解,与大模型直接相关的离职人员除已加入字节的杨红霞,还有去年离职的原语言技术实验室主任司罗,他是阿里两年前启动语言大模型 Plug(AliceMind)时的具体负责人。司罗拥有卡耐基梅隆大学计算机博士学位,曾任美国普渡大学计算机系终身教授,2014 年加入阿里担任 iDST (数据科学与技术研究院)NLP 团队负责人。
2020 年以来,达摩院还有原副院长金榕,两任自动驾驶负责人王刚、陈俊波等人工智能技术专家离开,金榕加盟推特担任研发 VP,后两者选择创业做清洁机器人。
百度是所有中国互联网大公司里,投入人工智能历史最久、曾经的人才阵容也最豪华的公司。自 2013 年百度在美国硅谷建立百度美研到 2017 年间,斯坦福人工智能实验室主任吴恩达、微软亚洲研究院院长张亚勤、微软全球执行副总裁陆奇等人先后加入百度。他们待的时间都不长,在 2018 年前后陆续离开。
一个有趣的交集是,OpenAI CEO 山姆·阿尔特曼(Sam Altman)从斯坦福退学前,曾在吴恩达管理的人工智能和机器人实验室工作过。
百度还是字节人工智能人才的重要来源。字节的技术负责人杨震原,目前大模型的负责人朱文佳,向朱文佳汇报的搜索负责人乔木均曾就职于百度。
在如今的大模型热潮下,大公司人才还会被创业潮分流。近期离职的大公司技术高管有阿里达摩院技术副总裁贾扬清,腾讯副总裁、平台与内容事业群(PCG)信息与服务线负责人郄小虎、京东首席科学家陶大程等。
贾扬清 2019 年加入阿里前任职于 Facebook,是知名 AI 框架 Caffe 的核心作者,他将在 AI 框架方向创业。郄小虎于 2020 年 9 月加入腾讯,任公司副总裁,负责 PCG 技术线,腾讯工作期间郄小虎参与了图像感知、视频文本检索等技术研究;陶大程是计算机视觉领域的专家之一,2021 年加入京东前,他曾在香港理工大学和新加坡南洋理工大学等高校任教。两人接下来的计划暂不清楚,创业是选项之一。
华为是另一家较早推出大模型的中国公司,于 2021 年发布盘古大模型。具体负责人为 2020 年 3 月入职的华为云首席科学家田奇,他此前是美国得州大学圣安东尼奥分校计算机系教授。通过华为 Mindspore AI 框架平台,华为还和中科院、鹏程实验室等机构联合开发了多个大模型,包括蛋白质结构预测大模型 “鹏程·神农”,支持图像生成的多模态大模型 “紫东·太初” 等。
算力和数据:过去有储备,未来面临不确定
清晰合理的战略目标,合适的团队与人才外,一家公司能否在大模型上有所建树,还取决于两个关键资源:算力和数据。
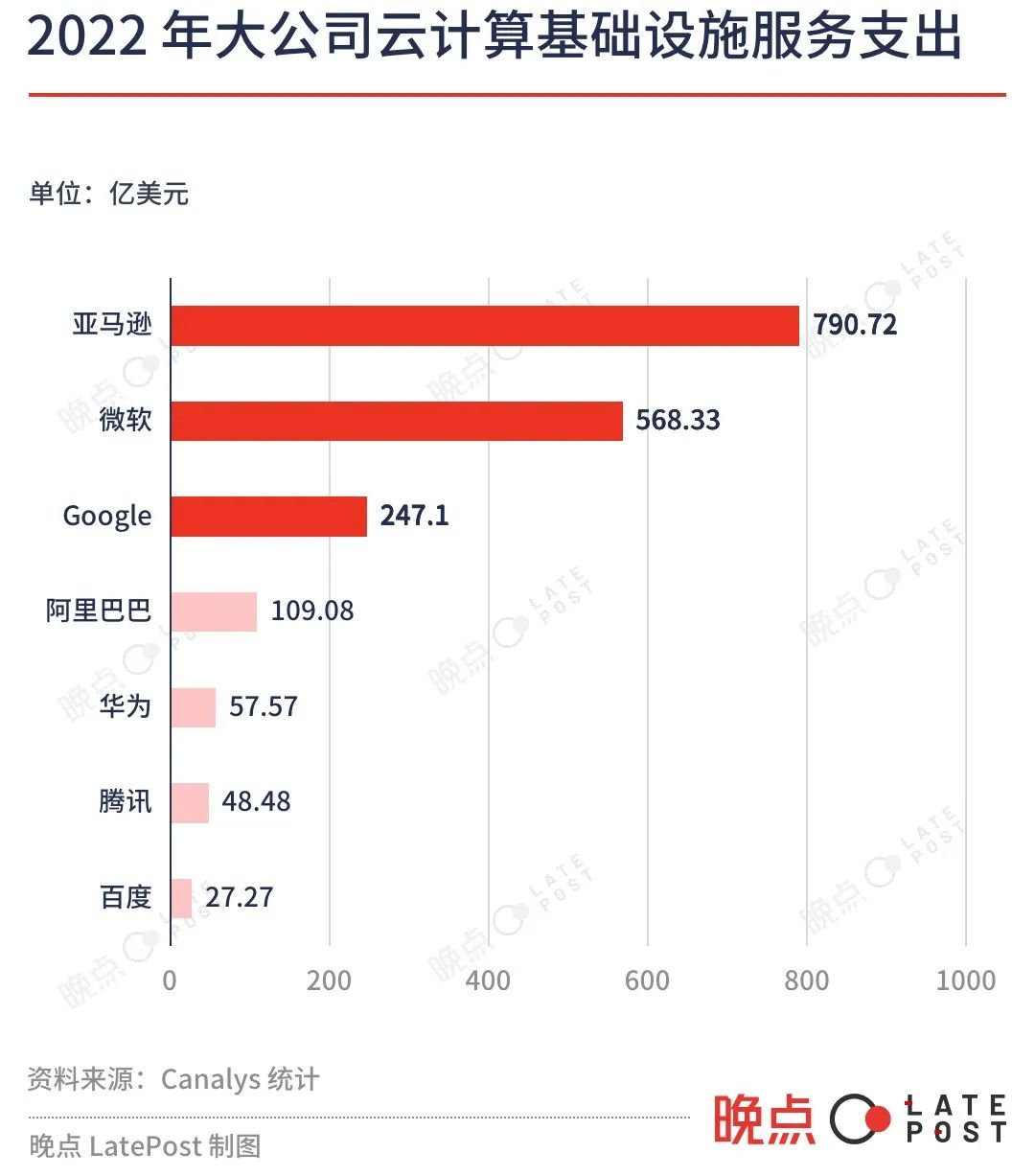
总体而言,中国公司过去两年的云计算、数据中心等算力基础设施开支小于美国大公司。不过就存量看,中国大公司过去有一定算力储备。
目前用于训练大模型的主力芯片是英伟达云端训练 GPU A100。据《晚点 LatePost》了解,字节跳动朱文佳团队目前可使用的 A100 约有数千张。为支持大模型开发,字节今年早些时候还将原本计划给商业化团队新增的一批 A100 调给了朱文佳团队。A100 目前的市价约 10 万元人民币 / 块,数千张 A100 的价值达数亿元人民币。
阿里 2021 年时曾披露,在训练十万亿参数的多模态大模型 M6 时,它们使用了 512 张英伟达 V100 GPU。它是 A100 的前序产品,A100 有大约 3 倍的性能提升。
华为在 2021 年曾披露,训练盘古大模型时,团队调用了超过 2000 块华为昇腾 910,进行了超 2 个月的训练。不过昇腾 910 最初设计为 7nm 制程,2020 年 9 月后,台积电等芯片代工厂不再能为华为生产高制程芯片。
一位关注大模型领域的投资人称,阿里、腾讯、百度、华为等国内主要云厂商过去都积累了大量 GPU。去年大模型热潮未起时,公有云上的 GPU 算力不是紧缺,而是 “愁卖”,云厂商甚至得亏钱卖资源,并与部分公司签订了长期锁价合同,这让热潮前就已入场的一些大模型创业公司 “花更少钱办了更多事”;也侧面说明大厂有一定算力储备。
但再往下,所有中国公司在获得更多算力上都面临不确定性。更多人训练大模型也会进一步加剧算力紧缺。
去年 8 月底,美国政府宣布禁止美国公司向中国大陆、香港和俄罗斯出口高端 GPU,设定的红线是:算力超过 4800 TOPS,且带宽传输速率超过 600 GB/ 秒,受限产品就包括英伟达 A100 和后续产品 H100。
为绕过这一限制,英伟达推出了 A800,算力与 A100 一致,但传输速率降为 400 GB/ 秒,不在被禁范围。不过这条路仍有变数。美国政府的系列禁令明确指向人工智能,不排除后续有超出预期的更严厉措施。
大模型的训练还需要海量数据。一种观点是,中文数据在数量和深度上均不及英文,所以中文大模型相比国外大模型 “先天不足”。
英语是强势语言,除文本量最大外,大量学术论文、专业文献也以英语撰写,高质量的公开英语数据库也更多。英语数据的广度与深度确实强于其它语言。
但数据对模型效果的影响是一个更复杂的问题。包括 GPT 系列大模型在内,主流大模型都基于最早由 Google 研究人员提出的 Transformer 架构,它会对不同人类语言,包括编程语言做高度抽象和压缩,这些语言在底层逻辑上有相似性,中文数据的不足可以部分由其它语言数据弥补。
大模型创业公司澜舟创始人、微软亚研院原副院长周明说:“现在的中文大模型都是在用多语言训练,语言结构有共通性,一件事如果英语表达得更好,中文也可以借鉴,形成生成结果。”
大公司的数据相比创业公司还有额外优势,他们能获得一些非公开的高质量中文文本数据。部分数据还带有真实的场景属性,如电商平台中的客服沟通数据。
如果把这一波浪潮比喻为大航海,OpenAI 是第一个到达新大陆的人,它已完成了最危险、最不确定的部分,即证明了超大参数模型的可行性和惊人效果。其它公司都是在沿着这个相对确定的方向做复现和优化。李彦宏在发布文心一言后曾说百度有信心在综合能力上,迅速追上甚至超过 ChatGPT。“很快” 可能很难实现,但把时间拉长,学习与模仿将拉平一批公司间的差距。
变数在于:中国公司未来可能无法通畅地获得更多算力,技术与人才的跨国流动也在变慢,招募更多大模型高端人才变得更难了。
成为中国第一的吸引和被颠覆的危险
宏观环境变化的另一面是,在中美市场更加分隔的当下,中国需要自己的大模型。中国市场又尚未出现明显的领先者,这使各大公司加速入场。
一位字节人士称,在去年底 ChatGPT 出现前,字节对大模型投入还比较少。表现之一是,约有 100 人的字节 AI Lab NLP(自然语言处理)组,只有不到 10 人在研究语言大模型,其它人主要在做翻译和抖音小安(内置于抖音的安全助手,有预防网曝、网络诈骗的功能)的优化。但今年 1 月后,大模型迅速成为 NLP 组重点工作。字节 AI Lab 可能会基于人工智能创业公司 HuggingFace 去年 7 月开源的大模型 BLOOM 做开发,它的参数达到 1760 亿,是目前最大的多语言开源语言模型。
这是低迷两年的互联网市场一个难得的增量空间,如果能在中国市场做到第一,就可能开辟巨大的新市场,或给已有业务,如云计算、游戏、社交等加上 “放大器”。
紧迫也来自,如果大公司自己不做,就有被颠覆的风险。
以利益分配结果看,技术创新有两种,一种果实多归属成熟公司,一种则会激发一批新巨头。
由 AlphaGO 战胜李世乭引燃的上一轮 AI 热潮更靠近第一种。当时的人工智能技术虽然在识别图片、人脸等一些特定任务上有高效率和准确率,但应用场景有限,且当时的产品不够强大和通用,没有好到足以动摇成熟企业已建立的市场格局。一个例子是,商汤、旷视等人工智能新锐公司在它们最主要的市场安防领域,难以撼动海康、大华的优势地位。
大模型则有可能是第二种创新。ChatGPT 和其它生成式 AI 产品及背后的大模型技术,迅速展现出了冲击现有商业模式的力量。
文生图应用 Midjourney 去年已获得超 1 亿美元收入,这家公司到去年 10 月只有 10 余名员工。在微软搜索引擎接入 GPT 推出 New Bing 后,Bing 访问量上升了 15.8%,Google 搜索引擎的美国市占率则下降了 1%。上周微软宣布 Bing 日活跃用户首次突破 1 亿,其中 1/3 是新用户。
当技术杠杆足够强时,大公司面对新机会时的包袱和协调难题就变得更为明显:
这包括与主营业务的冲突,Google 在搜索引擎上引入大模型时的犹疑是一个前例,各公司需要在以新技术打造全新产品,和用新技术提升现有业务间做综合安排与取舍。再往下是如何建立相应组织结构和多部门协作机制。相比没有退路的创业公司,当大模型商业进展遇挫时,业务颇多的大公司的热情能持续多久也是问题。大公司还面临更强的监管与伦理风险,大模型可能带来虚假信息和 “不正确” 的言论,亦有隐私问题,各国监管已在更早、更多地干预。部分国家已禁用 ChatGPT。
中国大公司发布的基于大模型的文本生成类应用,目前均未直接向普通民众大规模开放。文心一言需要内测码才能使用,阿里、腾讯和字节,近期可能都不会发布基于大模型的 to C 对话类产品。
巨头有更多的钱和资源,但当机会足够大 ,改变足够剧烈时,资源往往不是最难的部分。
来源:晚点LatePost 微信号:postlate
 微信扫一扫打赏
微信扫一扫打赏 支付宝扫一扫打赏
支付宝扫一扫打赏





