

2018 年冬天,临港成为上海自贸区新片区的时候,特斯拉没有 Model Y,OpenAI 没有 ChatGPT。
眼下,这两块招牌背后,电动汽车和生成式 AI 已是当下全球产业中最热闹的两件事。甚至前者在 AI 展现的新能力映衬下都显得有些 “传统” 了。
越来越多的人隐约有一种生活状态将被颠覆的感觉。电动汽车给埋在发动机旁边一百多年的油罐做了分离手术,如果越来越多人现在已经习惯了这一点的话,ChatGPT 又扛着新的 AI 大旗说,不止出行方式,整个人类的生产方式 —— 人类如何获取知识,如何写代码和工作方案 —— 都要彻底改变了。
上海临港悄然站到了这两场变革的关键位置。
现在这里是国内场景最丰富的自动驾驶测试场。特斯拉在美国本土之外的首座超级工厂几年前落在这里,另一座特斯拉储能超级工厂几年后也会在这里落地 —— 同样的,如果越来越多人现在已经习惯了这些的话 —— 距离特斯拉超级工厂 3 公里外的一座人工智能计算中心(AIDC)则正在愈发引来新的注目。
这个建筑面积接近 20 个足球场大小的空间里,安置了 5000 个服务器机柜和多达 27000 块 GPU,背后的建造者是商汤科技。
与这个 AIDC 的建造相隔不久,商汤科技在 2019 年第一次推出了自研的 CV(计算机视觉)模型,用 10 亿的参数规模实现了当时业界最好的算法效果。两年之后,商汤开始训练 30 亿参数的多模态大模型 “书生”,并在 2022 年开源。
4 月 10 日,商汤科技 CEO 徐立出现在临港 AIDC 的现场,背后是一张 AI 生成的图案,画面上是一个人类宇航员正在走入一个新的科技世界。

这个在复杂而具体的商业场景中成长起来的中国 AI 公司,正式拉开了自己的大模型叙事。
一整套大模型
商汤大模型研究的起点,可以回溯到 4、5 年前。
数据库 ImageNet 项目中有 1400 万张手动标注的图像,是目前世界上最大的视觉数据库。任何一个 CV(计算机视觉)模型都绕不开它。在利用 ImageNet 训练 AlexNet 模型时,可以大致衡量一个 CV 大模型的学习能力。
2019 年,商汤科技团队和新加坡南洋理工大学的研究者一起,用 512 块 GPU 把在 ImageNet 数据集上训练 AlexNet 的时间缩短到 90 秒,大幅提升此前腾讯用 1024 块 GPU 创造的 4 分钟最短时间。
数据库 ImageNet 项目中有 1400 万张手动标注的图像,是目前世界上最大的视觉数据库。利用 ImageNet 训练 AlexNet 模型的耗时,是高性能 AI 训练和计算的一个衡量尺度,关乎 AI 生产及后续迭代的研发效率。这次性能突破在行业之外并不惹眼,但对商汤科技在大模型研发中的架构能力发展意义重大。
商汤科技从 2018 年开始了 AI 大模型的研发,一年之后已经具备了千卡并行的系统能力。那两年是商汤在大模型研发的起步。2019 年,商汤自研了一个 10 亿参数的 CV 大模型,实现了当时业界最好的算法效果。
这个 10 亿参数的模型现在已进一步发展成一个 320 亿参数量的、全球最大的 CV 大模型,并且从去年开始在自动驾驶、工业质检等多个领域发挥作用。而这个 CV 大模型现在只是商汤科技大模型体系中的一个。
4 月 10 日的上海临港 AIDC,商汤科技首次公布了 “日日新 SenseNova” 的大模型体系。同样首次公布的,还有在 NLP(自然语言处理)、AIGC(人工智能内容生成)领域的多个 AI 大模型。

图源:商汤科技
依托于千亿级参数的 NLP 模型,商汤科技发布了最新的自研中文语言大模型应用平台 “商量 SenseChat”。
如同名字的字面意思,生成式自然语言大模型最重要的能力并不只是问答,在与人的多轮对话中步步逼近精准答案的能力同样重要。这考验着大模型在语义理解基础上的逻辑推演水平。
徐立在现场实时演示了如何用 “商量” 来完成童话故事的续写、邀请函的文本创作和细节修改。在展示中,“商量” 已经具备相当的逻辑推理能力,并且在多轮对话中展现了不错的上下文理解水平。

图源:商汤科技
商汤科技也展示了语言大模型支持下的几项创新应用,比如帮助开发者更高效地编写和调试代码,或者为用户提供个性化的医疗建议。值得一提的是,“商量” 在短时间内完成了对一整部《专利法》的理解,并且能够顺利的从中提取和概括信息来回答问题,答案准确。这显示这个语言大模型也具备了一定的对超长文本的理解能力。
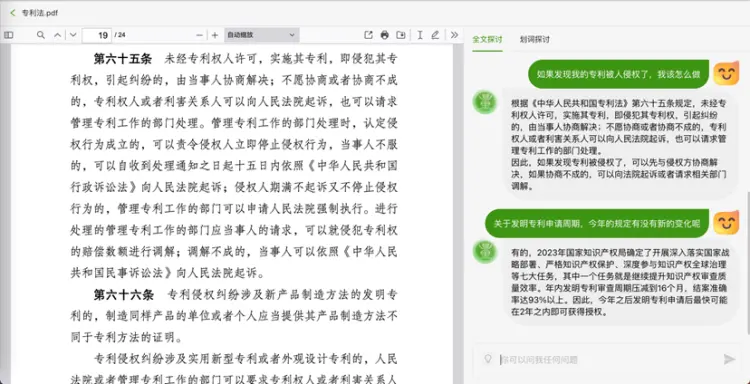
图源:商汤科技
基于这个大语言模型,商汤科技发布了包括 AI 文生图创作、2D/3D 数字人生成、大场景 / 小物体生成等一系列自研的生成式 AI 应用。
文生图创作平台 “秒画 SenseMirage” 展现了光影真实、细节丰富、风格多变的强大文生图能力,可支持 6K 高清图的生成;客户还可根据自身需求训练生成模型;AI 数字人视频生成平台 “如影 SenseAvatar” 仅需一段 5 分钟的真人视频素材,就可以生成出来声音及动作自然、口型准确、多语种精通的数字人分身。

图源:商汤科技
“琼宇 SenseSpace” 和 “格物 SenseThings” 则是两个 3D 内容生成平台。基于神经辐射场技术(NeRF),“琼宇 SenseSpace” 具备城市级大尺度的空间重建生成能力,只需要 2 天即可完成 100 平方公里的空间生成(算力为 1200 TFLOPS 的标准下),建模效率相当于传统人工建模的 500 人水平;“格物 SenseThings” 可实现各品类物体,包括光照和材质维度在内的细致还原,并且支持如航天器模型、室内盆栽等复杂结构物体的复刻。两套平台生成的各类 3D 内容都能够进行再编辑再创作。

图源:商汤科技
从 “秒画 SenseMirage”、“如影 SenseAvatar” 到 “琼宇 SenseSpace” 和 “格物 SenseThings”,可被视为一个完整的视频内容的制作和生成工具平台。人、物到空间的数字化闭环都包含在这套生成式 AI 应用矩阵里。将为未来短视频、直播产业带来生产力的提升。
这些都归于商汤科技 “日日新 SenseNova” 的大模型体系之下。
徐立表示,这个名字取自《大学》的第三章中,汤之《盘铭》的一句 “苟日新、日日新、又日新”。商汤科技也希望商汤大模型体系的迭代速度及处理问题的能力上可以日日更新。
做大模型,也做流水线工厂
一个大模型里,参数量与处理数据量的乘积,就是所需要的计算量。
Meta 在今年 2 月发布了语言模型 LLaMA,这个仅有 130 亿参数的语言模型在性能表现上超过了拥有十倍于它(1750 亿)参数的 GPT-3,这或许是一个新的趋势。
当计算量由于有限的可调用资源而被设定出一个上限时,大模型的迭代开始变成一个参数量与数据量的分配问题。大量权重会给到数据,因此现实场景中的垂直领域大模型,其参数量不能肆无忌惮的增长。
从一个通用的千亿(甚至万亿)大模型里追求智能涌现,然后蒸馏出百亿或者数十亿级参数规模的大模型,以此为垂直领域大模型的训练起点,这是目前 AI 领域大模型落地的研发思路。因此对于最终意在服务于具体场景的商汤科技来说,一个通用、全修的大模型是必须的。
但这只是基础。
从生产方式上,此前人类历史上闪耀的算法模型,从谷歌、抖音的信息流算法,甚至到 Bert 与 GPT-3,某种程度上都仍然出自小模型时代模型的生产方法。
在 ChatGPT 劈开红海后,关于大模型最曲折的一段共识道路已经走完。当大模型开始规模化的成为一种生产力工具,其批量生产所需要的算力以及资源效率需要一个新的生产范式。
这意味着大模型的研发已经从一场思维竞赛,过渡到一个数据获取和算力调配的效率竞赛。
“很多人认为,只要买了这么多 GPU,就可以去搭建超大规模的训练集群,这是很大的误区。其实训练人工智能大模型,造超级 AI 计算机去完成任务,我认为是工程的奇迹。” 陈宇恒表示。
过去 5 年,超大参数 AI 大模型的参数量几乎每一年提升一个数量级。过往的 10 年,最好的 AI 算法对于算力的需求增长超过了 100 万倍。但算力并不只是 GPU 数量的正相关。上万张 GPU 的并行效率背后是系统架构和网络架构设计的复杂工程。否则,虽然 1 万张卡和 1000 张卡理论来说是有 10 倍的训练速度,但实际上可能 1 万张卡只能有 1000 张卡 2 倍的训练效率。
集群框架的设计,数据存储等因素都是修炼大模型时需要前置的问题。换句话说,大模型的修炼开始普遍成为一个工程学问题。
如何让大模型的生产范式从小作坊转变到流水线工厂 —— 汤科技希望临港 AIDC 能成为那个工程学答案。
为什么是商汤
临港 AIDC—— 或者叫做 “SenseCore AI 大装置”—— 正是为此而搭建的。这是一个巨大的算力中心,也是一个融合了 “大模型 + 大算力” 体系的研发实体。

临港 AIDC 图源:新民晚报
临港 AIDC 在算力规模、并行训练能力以及稳定性方面的基础素质,使其可以为大模型研发提供强大的驱动力。
SenseCore 商汤 AI 大装置目前包含 27,000 块 GPU,可输出 5000 Petaflops 算力,是亚洲最大的智能计算平台之一。
以巨大算力规模为基础,SenseCore AI 大装置目前可支持 20 个千亿参数量的超大模型同时训练,并提供涵盖数据、训练工具、推理部署、性能优化一条龙的大模型基础设施服务体系,并提供涵盖数据、训练工具、推理部署、性能优化一条龙的大模型基础设施服务体系。
在 AI 大模型时代,衡量算力能力和核心指标不是简单的数字,其一是多卡并行状态下的有效利用率,即能够支撑大模型训练的实际算力;其二是系统能够持续稳定运行的时长。
SenseCore AI 大装置拥有出色的并行计算能力,能够以最大 4000 卡规模集群进行单任务训练,并可做到七天以上不间断的稳定训练。SenseCore AI 大装置在 2022 年已支持了超过 10 个大模型训练项目,其中不仅有商汤自身的大模型训练项目,也包含了一些其他企业自定义的模型训练任务。在 4000 卡规模集群的训练关键指标达到世界领先之后,SenseCore AI 大装置将为商汤科技未来万亿级参数规模的大模型训练提供基础。
算力层、以及平台层和算法层的三层结构组成了 SenseCore 商汤 AI 大装置的整体架构。基于 AI 大装置和 “日日新 SenseNova” 大模型体系,商汤科技也将面向客户提供涵盖自动化数据标注、大模型推理部署、大模型并行训练、大模型增量训练、开发者效率提升等多种大模型即服务(Model-as-a-Service)。

图源:商汤科技
某种程度上,大模型算法本身是大模型在实际场景落地中那个最容易跨越的环节,更多的矛盾集中在后续的工程能力,以及成本控制上。垂直领域大模型近年在技术上已经开始越过工业红线,但它的成本仍然太高。换句话说,AI 已经证明了 “能不能” 的问题,接下来的问题是 “够不够便宜”。
这些都是 SenseCore 商汤 AI 大装置在数据标注效率、模型部署成本等环节希望解决的问题。
“它不单是说在 AI 的生产上做了产品的壳,它是提供了一整套工具和产品以及解决方案,把人工智能大模型的新的生产范式去做整体的商业化,以及对外的服务,去推进人工智能领域的整个商业化的发展。” 陈宇恒这样描述 SenseCore 商汤 AI 大装置的角色定位。
换个角度,SenseCore 商汤 AI 大装置是一套 IaaS+PaaS 的产品体系。
从每个模型单独标注数据、单独训练的模式的 “小作坊” 模式,过渡到由少数大模型不断生产、迭代进化,由大模型支撑领域模型升级,再通过精调等手段,生产行业及场景模型,迅速达到应用标准的 “流水线” 模式。商汤科技需要这样一个大模型生产 “工厂”,在未来大量新的 AI 大模型的研发过程中尽早和产业场景做结合,从研发端开始压缩这条技术链路。
这决定了大模型研发降本增效的程度,AI 在生产和应用端的成本降低会引导出新的商业模式,这最终会缩短 AI 与现实的距离。
一位国内自然语言公司的从业者曾对品玩表示,“技术和场景,一家 AI 公司最好只选一头”。这句话的背景是 2016 年左右人工智能在国内激起的第一波浪潮,言下之意,彼时一穷二白的人工智能初创公司,需要集中精力先生存。
商汤科技也是在那一次浪潮中涌现出来的人工智能公司,但却是其中少有最终完成上市的一个。现在新的大模型浪潮涌动,作为一家人工智能平台型公司的商汤科技,面临的局面也今时不同往日。
当下大模型竞争的重要参与者,微软、Google 包括近日推出 Segment 的 Meta,大模型的背后都是坚实的场景支撑,并且两者会在很早期就开始融合。商汤的处境相似,一家人工智能公司要长久保持技术活力。需要在技术和场景两端同时建立脉络。
“技术和商业要齐头并进”,陈宇恒表达了类似的判断。这既是说大模型要尽早的进入现实环境中去自我优化,也可以理解为未来大模型的研发过程本身就要尽早放入相应的产业语境里来完成,以产品的形式来形成用户反馈的闭环。
而已经走入智慧汽车、智慧城市等领域产业深处的商汤科技,需要承担起这个未来大模型生产方式变革中的基础设施角色。
来源:品玩
 微信扫一扫打赏
微信扫一扫打赏 支付宝扫一扫打赏
支付宝扫一扫打赏





