


老黄又来掀桌了啦!
在今天凌晨的 2023 年全球超算大会( SC2023 )上,英伟达推出了全新 GPU H200 。
作为前代 H100 的升级款,老黄直接不装了,在官网上单方面将 H200 称为 “ 当世最强” 。

但更秀的是,没人会因此质疑他们违反广告法,因为在 AI 时代,对手们真只能眼巴巴地看着英伟达的车尾灯。
从英伟达官方透露的数据来看, H200 最强的就是在大模型推理表现上。
以 700 亿参数的 LLama2 大模型为例, H200 推理速度几乎比前代的 H100 快了一倍,而且能耗还降低了一半。
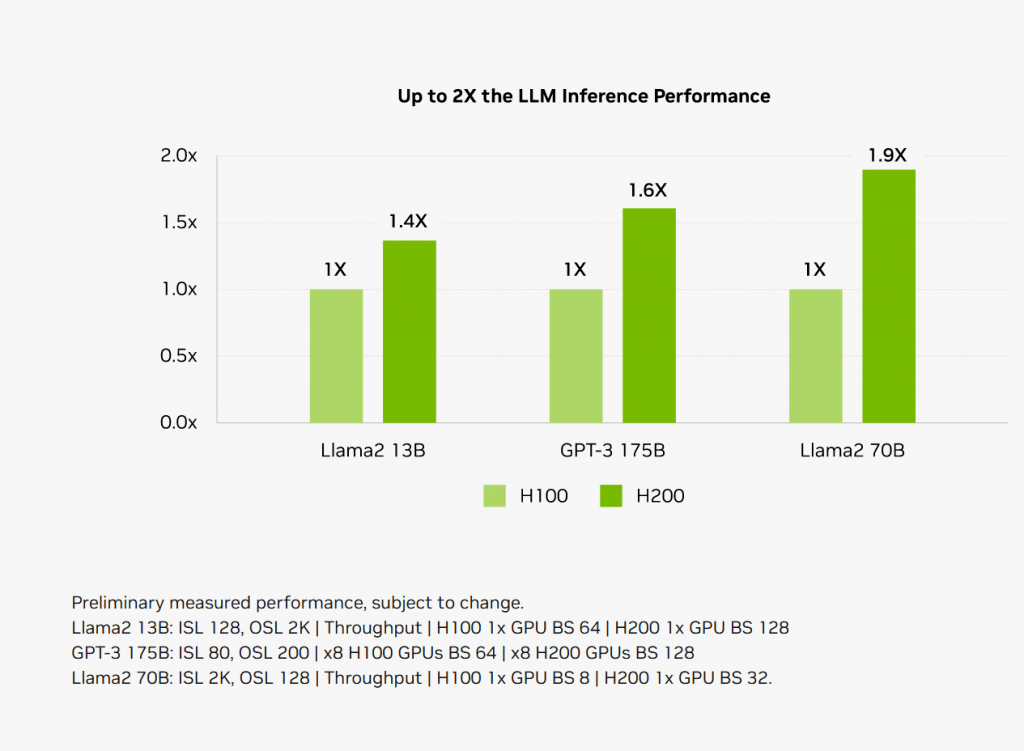
能取得这么强的成绩,自然是 H200 的硬件给力。
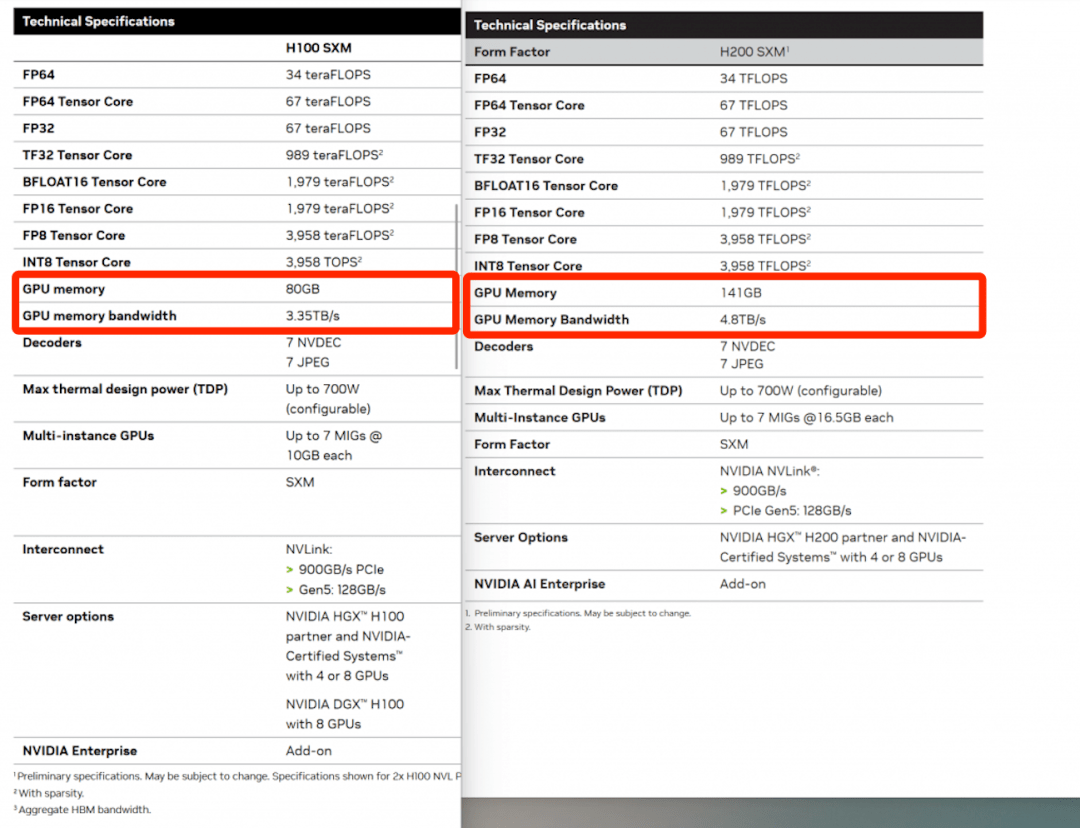
从参数方面看, H200 的主要提升就是把上一代 “G 皇” H100 的显存,从 80GB 拉到了 141GB ,带宽从 3.35TB/s 增加到了 4.8 TB/s 。
而这些进步则主要要归功于 HBM3e 内存技术。
今年 8 月的时候, SK 海力士推出 HBM3e 之后,据宣称单颗带宽可以达到 1.15TB/s ,相当于在 1 秒钟内传输了 230 部 FHD 高清电影(每部容量 5G )。
在 SK 海力士官宣 HBM3e 之后不久,包括三星、美光在内的内存厂商们,都陆续跟进了这一技术。

这个 HBM3e ,其实就是之前大家都在用的 HBM3 的升级版。
说白了就是有更高的性能、更高的带宽,好处就是芯片能用更快的速度传输数据,同时还降低功耗。
非常适合眼下的 AI 和大数据运用。
于是英伟达第一时间就找到 SK 海力士进行了合作。
所以我们能看到这才没多久, H200 就已经用上了这一新技术。

比起技术升级更方便的是, H200 和 H100 都是基于英伟达 Hopper 架构打造的。
所以两款芯片可以互相兼容,那些装满了 H100 的企业不需要调整,可以直接更换。
不过,乍一看好像是王炸,但实际上 H200 可能只是 H100 的一个 “中期改款” 。
因为我们发现, H100 和 H200 单论峰值算力的话,其实是一模一样的。
真正提升的参数只有显存、带宽。
而在此前,大家常用来评判 AI 芯片性能的重要参数:训练能力。
H200 相较 H100 的提升也并不明显。
从英伟达给出的数据来看,在 GPT-3 175B 大模型的训练中, H200 只比 H100 强了 10% 。
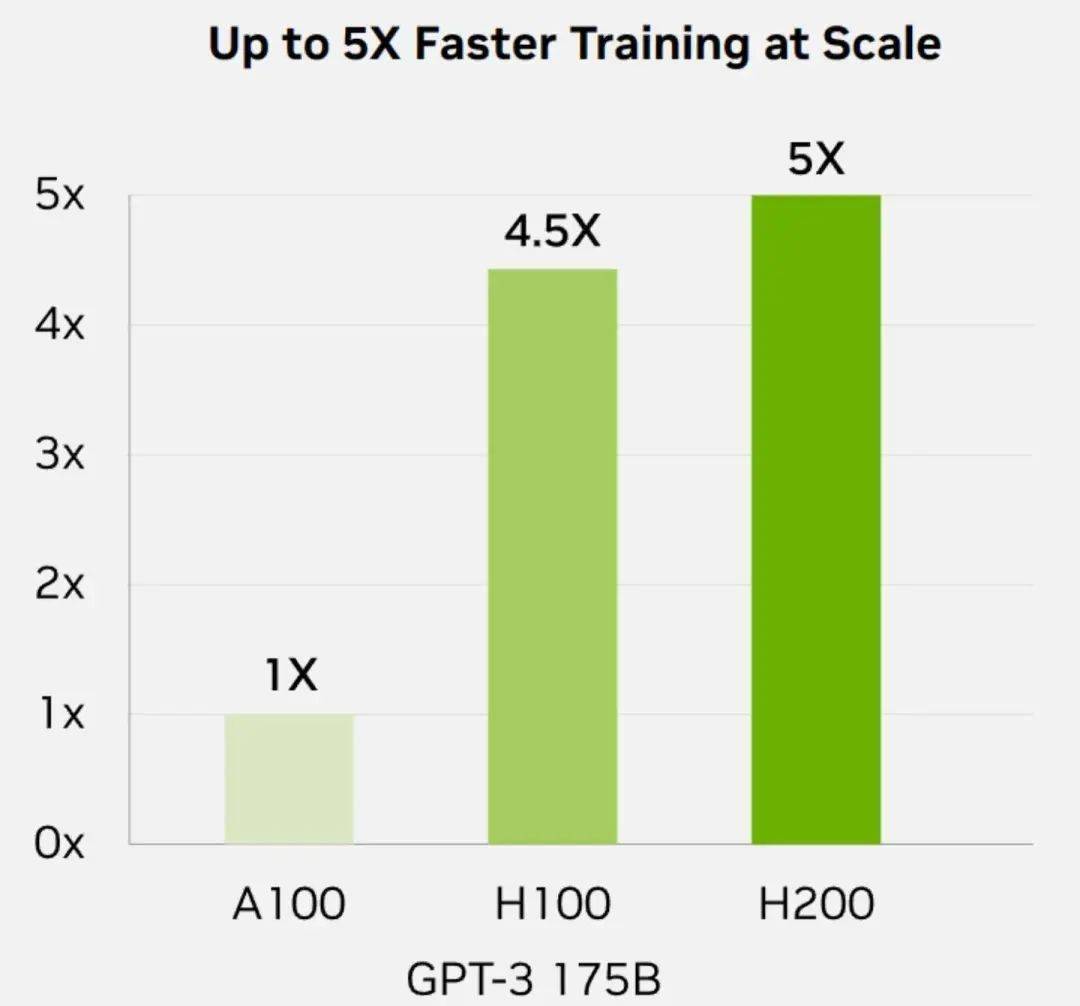
在世超看来,这种操作大概率是有意为之。
之前各个大厂忙着打造自家的大模型,对 GPU 最大的需求毫无疑问就是训练,所以当时大家的需求是提升训练能力。
而如今,随着 AI 大语言模型不断落地应用,训练模型在厂商眼中可能已经是牛夫人了,大家反而全去卷推理速度。
所以这次 H200 很可能是故意忽略 “算力” 升级,转而进行推理方面的发力。
不得不说,老黄的刀法依旧精准。

当然了,这也是英伟达工程师们给老黄挤牙膏的本事,谁让人家显卡真就遥遥领先呢。
哪怕只是做了个小提升, H200 还真就能当得起 “当世最强” 的名号。
而且根据瑞杰金融集团估计, H100 芯片售价在 2 万 5-4 万美金之间,那加量后的 H200 只会比这高。

而如今像亚马逊、谷歌、微软和甲骨文等大厂的云部门,已经付完钱排排站,就等着明年 H200 交货了。
毕竟,哪家大模型随便升个级不要几千个 GPU ?
只能说这波老黄又又又赚麻了。
但问题就是,加价对于 AI 芯片永远不是问题。
今年初创公司、大厂、政府机构等等为了抢一张 H100 挤破脑袋的样子还在上演,所以明年 H200 的销量根本不用愁。
“是人是狗都在买显卡” ,去年说完这句话的马斯克也不得不转头就加入 “ 抢卡大军 ” 。

更夸张的是,英伟达方面还说了,推出 H200 不会影响 H100 的扩产计划。
也就是明年英伟达还是打算卖 200 万颗 H100 芯片,也能侧面看出, AI 芯片是多么不愁卖。
但面对全球嗷嗷待哺的市场,英伟达其实也有点力不从心。。
像 OpenAI 作为打响 AI 革命第一枪的人,结果因为没有足够的 GPU 痛苦得不行。
比如因为算力不够用,自家 GPT 们被各种吐槽 API 又卡又慢;
因为算力不够用, GPT 更强的上下文能力始终没法全员推广;
因为算力不够用, GPT 们没法卖给客户更多专有定制模型。。。
光连 OpenAI 创始人奥特曼,就已经出来好几次炮轰过算力短缺。
而为了解决这个问题, OpenAI 也想了不少办法。
比如自研 AI 芯片、与英伟达等制造商展开更紧密合作、实现供应商多元化等等。
上个月初就有消息说 OpenAI 已经在找收购目标了。
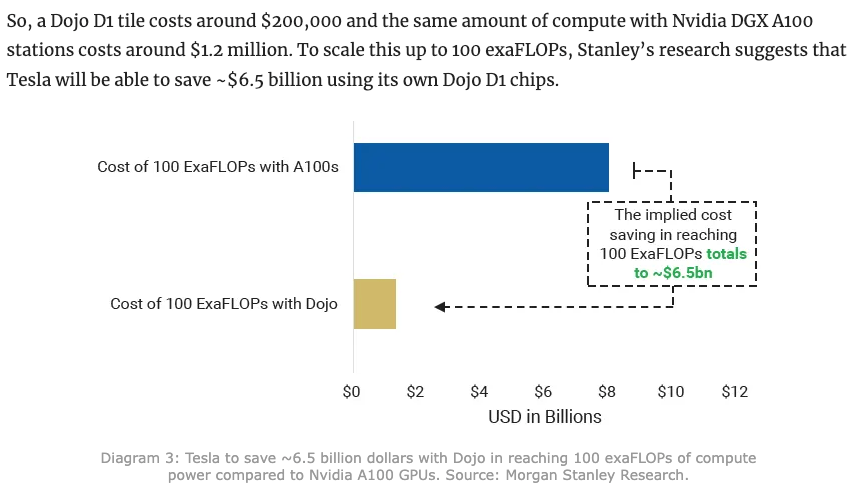
更进一步的是特斯拉,他们就在 7 月推出了由定制 AI 芯片 D1 打造的 Dojo 超级计算机,用来训练自动驾驶系统。
当时摩根士丹利直接吹了一篇研报说:特斯拉这波下来,比用英伟达的 A100 足足省下了 65 亿美元。
当然,这也不是说马斯克的这个自研的 AI 芯片就比 A100 强了。
而只是因为自研芯片只需要干自家的活,更符合自己需要、也没有算力浪费。
就好比英伟达的芯片是一锅大杂烩,谁来了吃都能吃饱饱;而自研芯片虽然只是小碗菜,但它可以按照个人口味做,虽然做得少、但更合胃口。
其他大厂也没闲着,比如微软要自研 “雅典娜” 、谷歌在年初就在自研芯片上取得突破进展。。
但就像我们前面说的,这次 H200 其实只是一个 “中期改款” ,还不足以打消其他厂商们的小心思。
按照英伟达自己放出的消息,大的还是明年会来的 B100 ,从图里看它至少是有指数级的提升。

所以世超觉得,大家伙忙活半天,在硬实力面前,黄老爷的位置恐怕还是会越来越稳。
你看像是即使强如 Meta 早在 2021 年就意识到,自己怎么干都比不上英伟达的 GPU 性能,转头就从老黄那下了几十亿订单( Meta 最近好像又有点自研的心思了 )。
还记得老黄刚宣布英伟达是 “AI 时代的台积电” 的时候,有不少人冷嘲热讽。
结果现在才发现,这句话居然是老黄的谦辞。
毕竟 2022 年台积电 “只” 占了全球晶圆代工产能的 60% ,而英伟达如今已经占据了可用于机器学习的图形处理器市场 80% 以上的份额。
总感觉,等老黄的大招真来了,这些大厂们的芯片自研项目恐怕又得死一片吧。
来源:差评
 微信扫一扫打赏
微信扫一扫打赏 支付宝扫一扫打赏
支付宝扫一扫打赏





