



文丨贺乾明 邱豪
编辑丨黄俊杰 龚方毅
8 月下旬,英伟达召开例行全员会。当时英伟达股价随着销量大涨,市值稳定地回到万亿美元以上,员工手中股票的价值已经是年初的三倍多。英伟达 CEO 黄仁勋提醒他们,不要太早激动,公司的市值会到 2 万亿美元。
全球只有苹果、微软、Google 的市值到过 2 万亿美元,各自牢牢抓住十多亿用户。它们也全部都是英伟达成为万亿公司的原因。ChatGPT 火爆后,它们向英伟达下了总额数十亿美元的大订单。
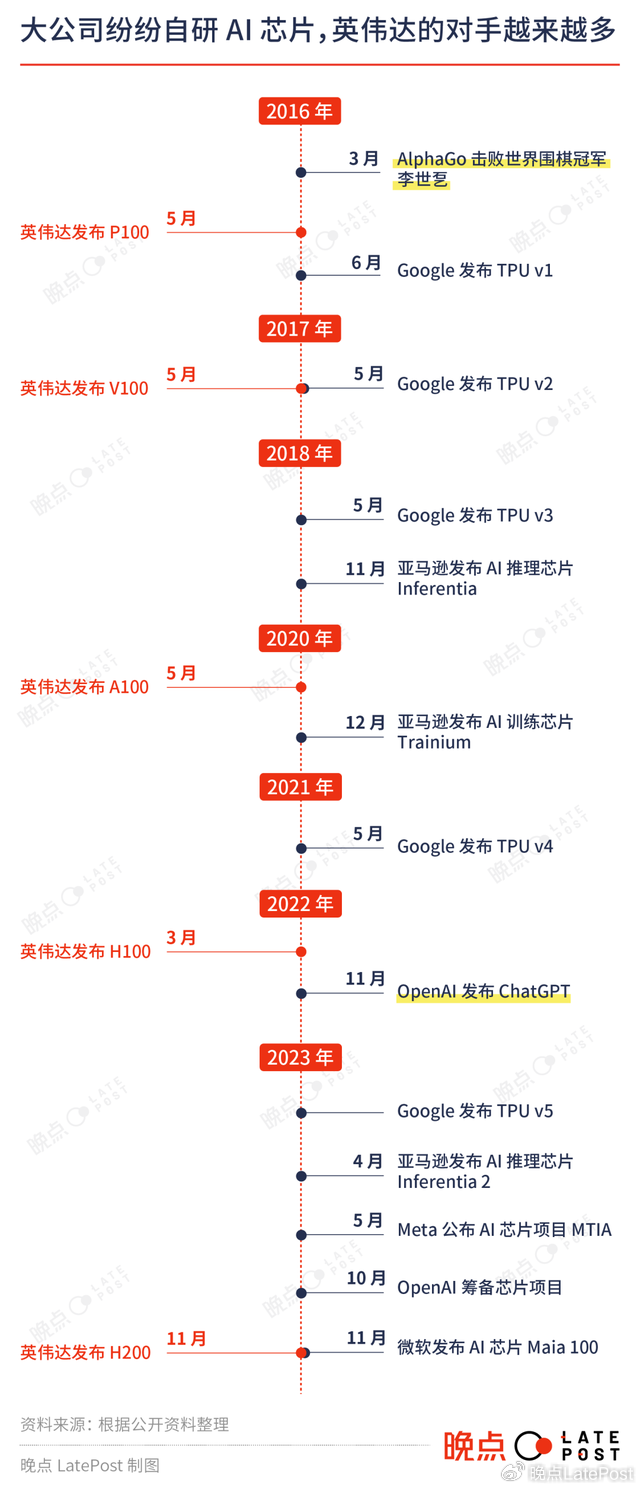
本周,英伟达发布了新款 GPU H200,与上一代最大的差别是用了新款内存芯片,连计算能力都没明确公布,其市值就应声涨了 700 多亿美元。英伟达称已经给 H200 找到了买主——明年它会密集出现在亚马逊、Google、微软等公司的数据中心中。
在英伟达冲向 2 万亿美元的道路上,这些客户还会继续下大订单,但也会和它直接竞争。今天微软的 Ignite 大会是这种关系的直接体现,微软一边发布自研的 AI 芯片 Maia 100,一边邀请黄仁勋到场宣布新的合作。
微软之外,Meta、Google、亚马逊、特斯拉等英伟达的大客户,今年都投入更多资源研发 AI 芯片,甚至 OpenAI 都开始筹备芯片项目。
两倍于 LVMH 的利润率,大客户们自研芯片的动力
英伟达成立至今 30 年,前 20 多年专精于游戏显卡这一个小众市场。加密货币带来的巨大挖矿需求让英伟达激活了显卡销量,英伟达的业绩和市值因此跃升,不仅收入在 2018 年冲破百亿美元、利润率冲上 30%,股价也在 2016 年到 2018 年 10 月间大涨 800%。随着比特币在新冠疫情肆虐之际冲上 6.8 万美元,英伟达的市值也逼近万亿美元,成为最值钱的芯片公司。
2023 年 3 月发布的 GPT-4 点燃了整个人工智能行业。根据芯片研究机构 SemiAnalysis 获取的信息,OpenAI 用 2.5 万张英伟达 A100 GPU 训练了三个多月,才做出 GPT-4 大模型。
A100 是英伟达 2020 年发布的 GPU。在 GPT-4 发布前几个月,英伟达推出了 H100 GPU,把计算能力提升到 A100 的 3 倍,专门为 Transformer 架构(大模型的底层)做了优化——当时 ChatGPT 还没有面世。
对于想要研发更强大模型的 OpenAI 和追赶 OpenAI 的公司,H100 都是需要大量囤积的战略资源,它立即变得供不应求。OpenAI 发布 GPT-4 后,两度因为 GPU 短缺停止付费用户注册。
埃隆·马斯克(Elon Musk)说 H100 “比毒品都难买”。迫切需要算力的公司们,转而订购 A100。受美国政府贸易限制,中国公司只能购买降低性能的 A800 和 H800。这些 GPU 的产能也远远跟不上需求。
红杉资本在今年 9 月称,许多公司的增长瓶颈不是客户需求,而是英伟达最新 GPU 的产能。
英伟达是设计公司,并不直接生产芯片,它需要请台积电生产芯片,从其他公司采购高性能内存,再交给供应商组装成一张卡。一颗 H100 的成本约 3000 美元,而英伟达卖 30000 多美元,翻十倍:
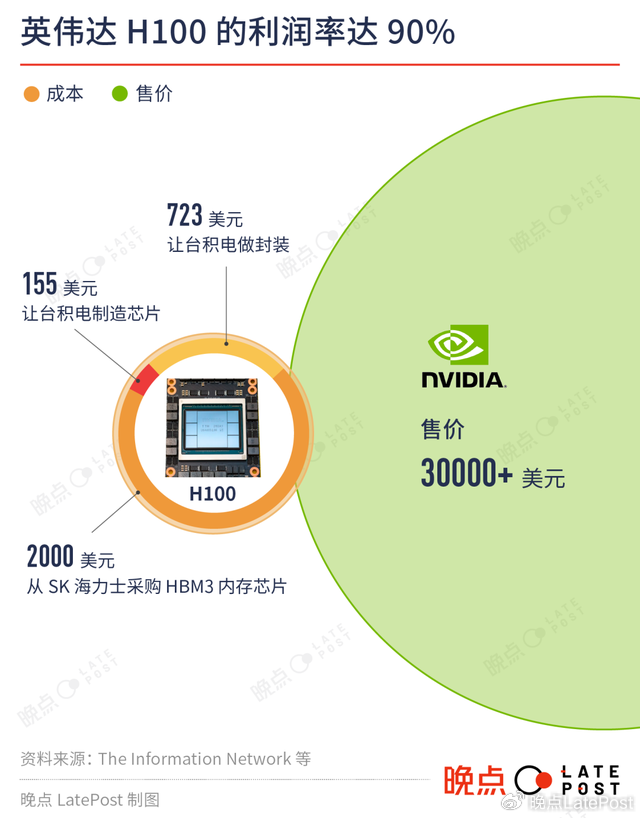

– 英伟达向台积电下订单,用 4 纳米的芯片产线制造 GPU 芯片,平均每颗成本 155 美元。
– 英伟达从 SK 海力士(未来可能有三星、美光)采购六颗 HBM3(High Bandwidth Memory,高带宽内存)芯片,成本大概 2000 美元。这是因为 GPU 处理大模型任务,还需要搭载比手机、电脑更大、数据传输速度更快的内存,才能保证效率。
– 台积电芯片产线生产出来的 GPU 和英伟达采购的 HBM3 芯片,一起送到台积电 CoWoS 封装产线,以性能折损最小的方式加工成 H100,成本大约 723 美元。
– H100 被送到其他英伟达的供应商处,4 颗或 8 颗组装在一起,加上数据传输单元,做成服务器。
利润丰厚的 H100 推动英伟达利润率攀升到 40%,超过了所有芯片同行,达到全球最大奢饰品集团 LVMH 的近两倍。
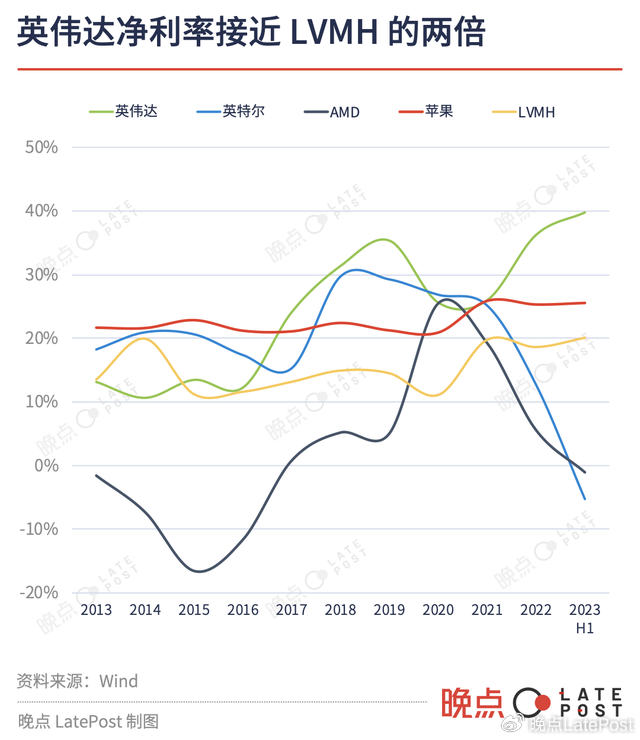
英伟达高昂的利润,就是它客户的成本。为了借着大模型浪潮抓住用户、激活业务,许多大公司采购 GPU 后,不惜赔钱对外提供服务。GPT-4 发布后,微软将其用于必应搜索,让用户免费使用。
黄仁勋常说的 “买得 GPU 越多,省的越多” 成为过去式。大公司买得越多,英伟达赚的越多,它们亏损越多。一个显而易见的选择出现了:自研一款芯片,可能省的更多。
过去十多年,研发一款芯片的难度持续下降:台积电、三星等代工厂存在,让它们不用担心芯片代工问题;芯片人才充分流动,降低了设计芯片的难度。
芯片研究机构 SemiAnalysis 的首席分析师迪伦·帕特尔(Dylan Patel)说,自研一款类似微软 Maia 100 的 AI 芯片,每年的成本大概 1 亿美元——对于研发费用每年上百亿美元的大互联网公司来说,并不算什么。
ChatGPT 带动了大模型热潮,大公司不用担心使用场景问题。咨询机构 Gartner 今年 8 月预测,全球 AI 芯片市场规模随着 ChatGPT 火热快速增长,到 2027 年就会达到近 1200 亿美元,是去年的 2.7 倍。
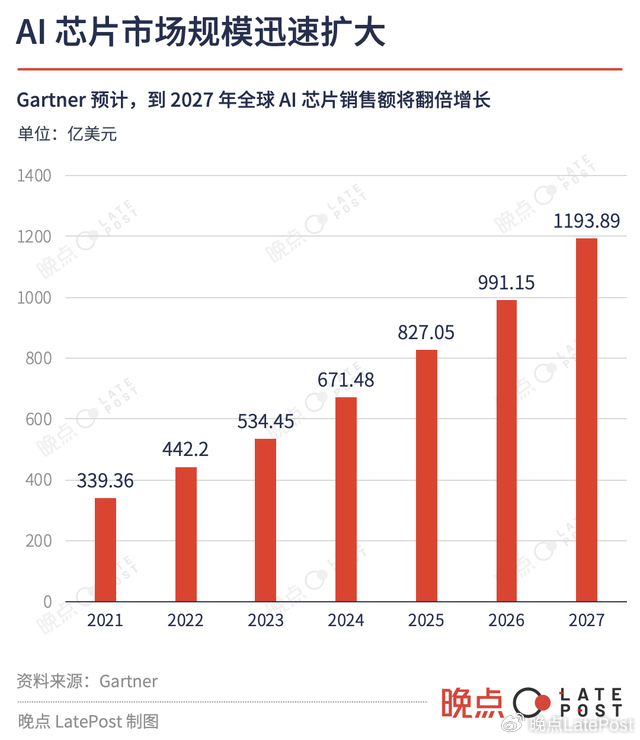
大公司们想在 AI 芯片研发能力上追上英伟达,投入 5 至 10 年也不一定能实现。不过它们只需要花英伟达同样的成本,做出十分之一的效果,就已经有利可图了。
训练更强的大模型,需要很多 GPU。“训练一个对标 GPT-3.5 的大模型,用 2000 至 3000 张 A100 GPU 就可以。但想要训练对标 GPT-4 的大模型,上万张 GPU 只是一个入场券。” 一家中国科技公司的大模型负责人说。
训练完成还不是结束。当用户使用大模型的时候,这些企业得靠 GPU 调动大模型 —— 即大模型推理。大模型要处理用户输入的问题,基本上每个字都要单独跑一遍大模型。给出回复时,类似的情况还要再来一遍。参数上千亿的大模型,每次跑一遍都要调用多张 GPU。
多位大模型从业者估算,如果千亿参数或更大的人工智能模型被广泛使用,大模型的训练成本和推理成本会达到 2:8,甚至 1:9。推理 GPT-4 或更强的大模型,基本上离不开英伟达高性能的 GPU。
《晚点 LatePost》了解到,参数更大的大模型推理会产生巨大算力需求,而且不可能在本地设备上实现(70 亿参数的大模型就需要 14G 内存,超出了所有手机的硬件配置和绝大多数电脑配置),不少英伟达员工因此相信公司市值会继续上升。
科技公司自研 AI 芯片,出发点都是推理参数较小的模型,然后再进一步扩展。阿里巴巴的含光 800、百度的昆仑芯片都是推理芯片,Google、亚马逊、特斯拉做 AI 芯片,也是从推理入手,然后再做训练芯片。
自研芯片不用向英伟达交税,性能低一些也能节省成本。根据迪伦·帕特尔等人的测算,按照 Google 的报价,使用其最新的 AI 芯片 TPUv5e 在训练、推理参数少于 2000 亿的大模型时,成本低于用 A100 或 H100。
大公司通常先在自己的业务中使用自研 AI 芯片,比如 Google 的 TPU 最先支持的是 Google 翻译,最新的 TPUv5e 首先用在了 Google Brad 和一系列用大模型改造的业务中(比如 Gmail)。微软 Azure 芯片部门副总裁拉尼·博卡尔(Rani Borkar)今天在发布会上说,微软正在必应、Office 等业务中测试自研的 AI 芯片 Maia 100,预计明年初投入使用。
芯片经过内部测试后,大公司会通过云计算平台对外提供服务,与英伟达争抢客户。11 月 8 日,Google 投资的 Anthropic 宣布大规模部署 TPUv5e,处理其大模型 Claude 的推理工作,这些任务原本属于英伟达的 GPU。
英伟达 2 万亿美元攻防战
“我们不需要假装公司一直处于危险之中。事实上,我们一直处于危险之中,而且我们深有体会。”11 月 9 日,黄仁勋在一场活动中说。
芯片行业先驱、英特尔联合创始人安迪·格鲁夫(Andy Grove)曾说 “成功滋生自满,自满导致失败,只有偏执狂才能生存”。英伟达也是硅谷最偏执的公司之一,从管理风格到战略蓝图都是。
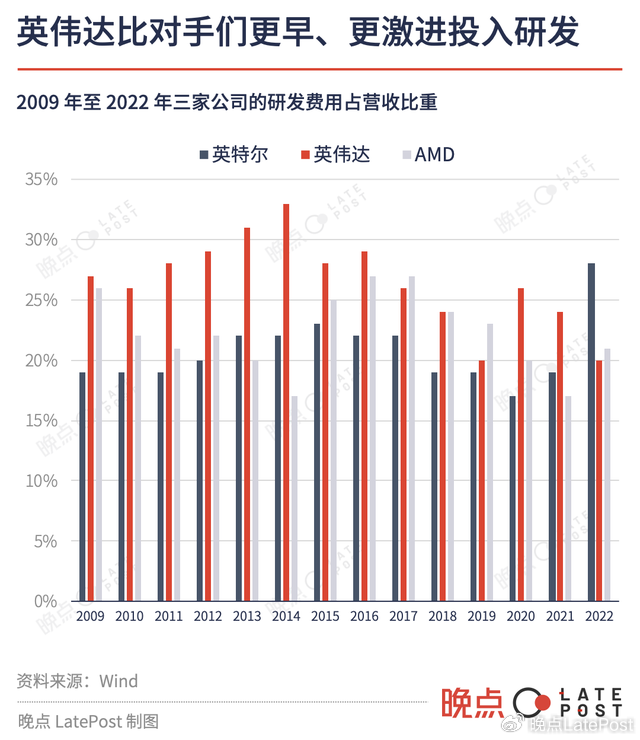
大约十年前,黄仁勋在俄勒冈州立大学向台下的毕业生传输经验:“当有人全力以赴时,他们就能做你做不到的事情。全力以赴,不留后手。” 他从不对冲风险,也不会多重押注,只在自己觉得对的路线上全力押注。
从 2006 年开始,为了让 GPU 在游戏、电影之外也有用武之地,英伟达将大笔资金投入到 CUDA 研发中,投资人和华尔街的分析师们不理解,为什么要给游戏显卡不断增加计算性能、让它们越来越贵和难卖?
直到大约十年后,人工智能和深度学习展现了商业价值,英伟达早期投资得到认可,CUDA 成了英伟达隐形的护城河。
为了顾及手机、笔记本电脑的功耗,苹果、英特尔等竞争对手的芯片常常一年只能提升不到 20%。而英伟达的 AI 芯片只考虑性能这一个目标。
黄仁勋不满足 “摩尔定律” 每 18 个月性能翻一番,他提出了更快的 “黄氏定律”,并要求团队以此为目标,两年发布一款新品,保持计算性能的绝对优势。明年 3 月,英伟达将发布下一代产品 GPU B100,预计性能会大幅度超过 H100 和加速追赶的所有竞争对手。
虽然从 P100、V100 到 A100,功耗都在 250W 到 400W 之间,而 H100 的功耗直接来到了 700 W,是 FPGA 或 ASIC 路线下 AI 芯片功耗的数十倍。但更强的计算性能,让英伟达的 GPU 拥有着不可替代的地位。
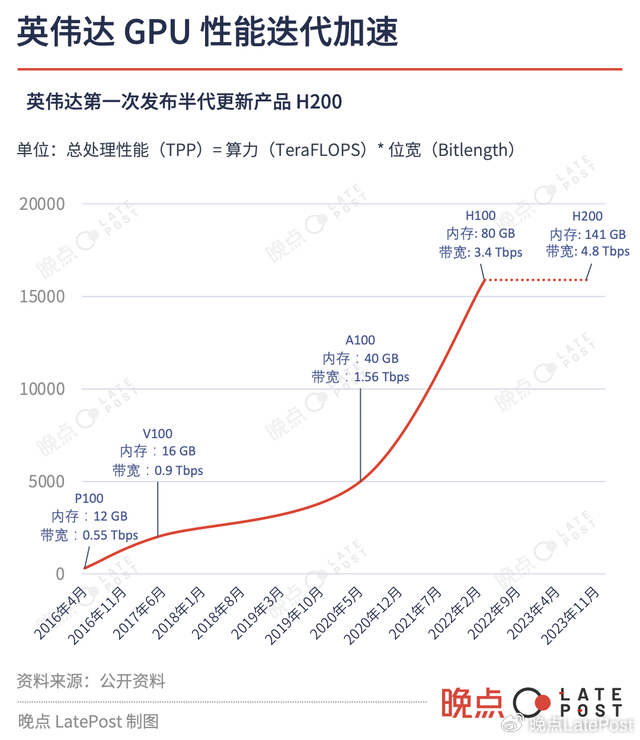
面对更激烈的市场竞争,英伟达加快了新品推出速度。11 月 13 日刚发布的 H200,是英伟达第一次在两代旗舰产品中插入一个 “过渡款”。据 SemiAnalysis 的信息,英伟达将在 2025 年发布 B100 的下一代产品,发布周期从之前的两年一更,加速到了一年一更,还会延续下去。
芯片市场需求和产能经常错置,但黄仁勋从不在意周期。一旦有重要且抢手的零部件,他就会下单锁定产能,哪怕冒着用不完的风险,也要确保自身供应,挤压竞争对手。
目前 AI 芯片供应瓶颈主要是 CoWoS 先进封装和 HBM3,英伟达包下了台积电约六成 CoWoS 产能,向 HBM 的三家供应商 SK 海力士、三星和美光下了巨额订单。
根据英伟达财报,截至今年 7 月底,英伟达账上还有价值 111.5 亿美元的订单、库存和产能采购承诺,另外还有 38.1 亿美元的供应合约预付款 —— 同行里没有第二家公司有这么多的库存和预付款。
英伟达的大手笔采购,让供应商都感到担心。台积电董事长刘德音在今年二季度业绩会上说,看不清楚 AI 的火热需求是不是短期泡沫。但英伟达的订单就在那里,台积电只能选择大幅扩产跟上。
在英伟达的一再追单下,台积电已经计划将明年的 CoWoS 产能提高到 3.5 万片 / 月、同比增长 120%。
这样极致的供应链掌控策略刻在英伟达的基因里。1997 年,黄仁勋向台积电下了 1.27 亿美元的代工订单。台积电创始人张忠谋每隔一段时间就要回访,重听一遍黄仁勋的业务讲解、确保他真的需要这么多晶圆——那年英伟达的全年营收只有 2700 万美元。
英伟达还拿出了奢侈品行业惯用的 “配货” 策略。渠道商和客户们想要 H100、A100 这样的旗舰芯片,就得先买够一定量的 L40S 等适合更小模型的推理芯片,无形当中将竞争对手从够得到的市场赶走。
地缘政治是英伟达面前最大的阻碍。上一财年,中国市场为英伟达贡献了 47% 的收入。美国政府在去年和今年 10 月两度收紧高性能芯片出口,英伟达是最主要的限制对象。
英伟达的反击就是贴着红线出新品。第一轮管制后不久,英伟达就将 A100 的带宽缩水,交出既符合规定,同时不影响算力的中国特供版芯片 A800,接着在半年内继续交出旗舰芯片 H100 的替代版本 H800。
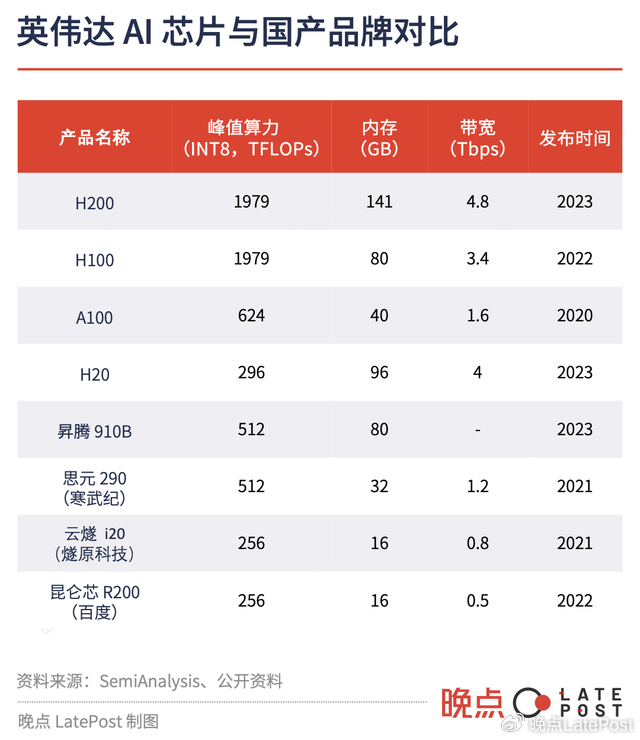
今年 11 月初,美国更新芯片禁令不到一个月,英伟达又拿出了符合新要求的 H20 GPU。虽然 H20 单卡算力只有 296 TFLPOS,是中国公司顶级 AI 芯片的 57%,但更高的内存、带宽都保证了它可以串联起来使用,买得够多就依然有很强的竞争力。英伟达股价跟着上涨近 10%。
把客户的客户变成自己的客户
全球的万亿美元公司,除去沙特阿美,都是黏住几亿甚至几十亿消费者的科技公司。
英伟达是当中异类。它的品牌长期只覆盖少数 PC 游戏用户,现在 50% 收入来自寥寥数个大型云计算公司和互联网巨头:亚马逊、微软、Google、Meta、字节跳动、阿里巴巴等。
大公司购买英伟达的处理器有一部分是自用,但更多是将其通过云计算平台租给其他客户。客户关系最终还是留在这些云计算平台公司手上。如果有一天,它们有了性能足够强的产品,随时可以换掉英伟达。
英伟达靠着 CUDA 绑定了数百万 AI 开发者,吸引着大型云计算公司采购它的 GPU。如知名分析师本·汤普森(Ben Thompson)所说:“英伟达既不是一家硬件公司,也不是一家软件公司:它是一家将两者融为一体的公司。”
现在这套逻辑依然成立,在人工智能前沿探索中,CUDA 仍然让英伟达的 GPU 具备优势。但现在黄仁勋还要再进一步,直接把云计算平台的客户变成自己的。
今年 3 月,GPU 最稀缺的时候,英伟达推出云计算服务 DXG Cloud:英伟达把卖给云计算公司的 GPU 租回来,由英伟达员工进一步优化,再出租给需要 GPU 算力的客户。
一来一回,云计算平台承担了数据中心的建设成本,客户却去了英伟达。但微软、Google、甲骨文依然加入了英伟达的计划。作为回报,它们很快就有了最稀缺的 H100。全球最大的云计算供应商 AWS 拒绝合作,直到今年 7 月才上线了 H100 算力出租服务。
“这是我们有史以来最大、最重要的业务模式扩展。” 黄仁勋说,“英伟达不仅为云计算公司提供 GPU,还把自己推向市场。”
OpenAI CEO 山姆·阿尔特曼(Sam Altman)近期接受采访说,虽然今年 GPU 紧缺,但明年情况会更好。因为 Google、 微软等公司自研的新款 AI 芯片将会投入市场。OpenAI 已经开始测试微软发布的 AI 芯片。
“这就是资本主义的魔力,现在很多公司都想成为英伟达。” 阿尔特曼说。而英伟达的步步紧逼,也没有给他们其他选择。
来源:晚点