
@高飞:Claude 3 用几分钟,搞定了语言学家两年的工作,也是一个惊人的案例。(昨天我们发了一个Claude3几分钟搞定了新量子算法的,今天这个是文科语言学的,人类是不太容易横跨这么大的知识领域的)
原文作者叫An Qu(hahahahohohe on X.com),在X上发布了一个使用Claude3的案例。具体而言,他用了几千个翻译对数据,就实现了一个小众语言的理解翻译,达到了一个专业学者两年的工作。他在 GPT-4 上进行了相同的测试,就失败了。(看好OpenAI近期发布某些重大更新,不然有落伍之忧)
全文如下:
**
今天在测试 @AnthropicAI 的新型模型 Claude 3 Opus 时,我经历了一件令人震撼的事,感觉仿佛见证了一个奇迹。虽然不想听起来太夸张,但这真是我当时的感受。
背景很重要:过去两年里,我一直在为我的母语——车臣语(Circassian)研究自然语言处理(NLP)。车臣语资源非常稀缺,在互联网上几乎无迹可寻。它属于孤立的车臣-阿布哈兹语言群,没有任何相关的语言。复杂的形态结构和有限的数据资源,让它成为了语言模型面临的一大挑战。
这几年,我艰苦地从少数资源中整理出了64K对翻译配对,并利用特定的模型(如T5、MLM-100、NLLB-200等)成功实现了俄语-卡巴尔迪安语的机器翻译,取得了不错的成绩。
我决定对 Claude Opus 进行一项试验。我发起了一个新对话,只上传了5.7K随机选取的翻译对,这只是我64K数据集中的一小部分,甚至没有覆盖全部的词汇量。我想看看它是否能够基于这些例子翻译新的句子。
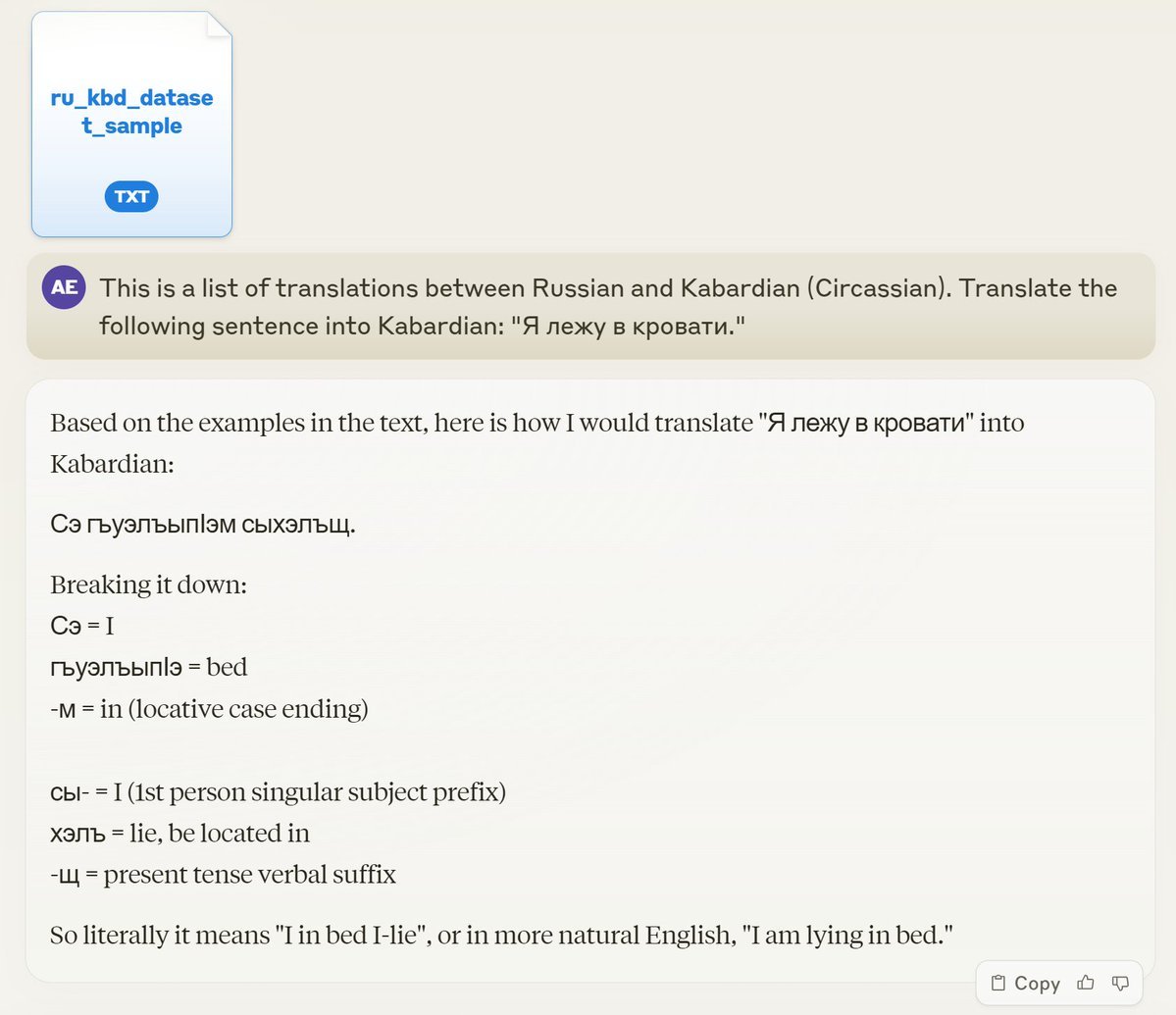
我没怀有太多期望,仅仅是让它将一个简单的句子——“我躺在床上”从俄语翻译成车臣语。Claude 不仅提供了完美的翻译,还详细解析了语法和形态学结构。
起初,我以为这只是碰巧,这个特定的句子可能正好在提供的例子中。但并非如此。
我尝试构造了一个独一无二、极不寻常的句子,理论上不可能存在于数据中。结果,Claude 再次提供了无懈可击的翻译和分析。仅仅依靠极少量的数据,Claude 的表现竟然接近于我为机器翻译特别训练的模型。这让我难以置信。
进一步的测试包括文学作品中的复杂段落、最近的新闻报道,甚至是语法和书写系统都显著不同的车臣方言文本。Claude 一致地展现了对语言结构深刻的理解,智能地推断出未知词汇,恰当使用借用词,提供可能的词源分析,在翻译中保留原文风格,甚至在需要时创造新词。所有这些成就都是基于仅几千个翻译对完成的。车臣语是一种具有复杂形态结构和语法的黏着语言。
要完成这些任务,需要深入理解语言本身,若由一个不熟悉这种语言的语言学家来做,可能需要至少一年的时间。然而,Opus 仅仅通过5.7K个随机翻译对,在不到一分钟内就轻松掌握了这些细微之处。
作为对比,我在 GPT-4 上进行了相同的测试,结果完全失败。它甚至无法翻译最简单的句子,更不用说理解语法的复杂性了。我之前也试过在类似的数据集上对 GPT-3.5 进行微调,但得到的也只是杂音。
我不确定 Anthropic 是如何做到这一点的,但这明显与其他任何东西都不同。虽然许多人对其在合成基准测试中的领先地位表示怀疑,但我亲眼见证的,在一个全新且极具挑战性的基准测试上取得的成果,确实令人震惊,这在训练数据集中几乎是不可能的。
为了排除潜在的数据污染,我尝试了相同的提示,但没有附上样本翻译,结果Claude无法进行翻译,并表示不熟悉车臣语。
这一发现意义重大。我两年辛苦工作的成果,Claude 只用几千个示例就轻松实现了。这对于资源匮乏的语言来说,无疑是一次飞跃,对许多其他领域也同样有着深远的影响。
我原本以为这样的进步需要多年才能实现,但它已经发生了。未来已经到来,而且它令人惊叹不已。
@木遥:原作者后来发了个更新,发现自己弄错了Claude 3并不是完全不懂车臣语,所以不是纯粹通过样本学会的(当然结果还是很好,但没有「那么」神奇