


“我听说 o2 在 GPQA 上获得了 105%。” 几天前,山姆・奥特曼在 X 平台上突然发了这么一句话,但马上又写道,“见鬼!账号错误!”
这位掌控 OpenAI 公司的 CEO,就这样以如此戏剧性的玩笑方式透露了 OpenAI o2 的进展。GPQA(Graduate-Level Question Answering)是一项研究生水平科学知识问答能力的基准测试,此前,OpenAI o1 在这项测试中仅得到 78% 的成绩。
o2 的得分也大概率不会超过 100%,但这番 “鬼才营销” 仍然引起了全网热议。
当国内大模型领域还没有复刻出 o1-preview 一星半点的时候,OpenAI 已经在 “有意” 透露具备多模态能力的完整版 o1 了。它能看懂并正确解答复杂数学题,识别人类史上首张黑洞照片,这使得外界对 o2 的能力更为好奇,也吸引一众国内大模型玩家朝着 o1 跃跃欲试。
“AGI 有救了。” o1 发布那天,李江一早就把一篇介绍 OpenAI o1 的科普文章从头读到尾,一颗心稍微沉下来些。
过去几个月,李江一直处在焦虑之中。GPT-5 迟迟没有发布,一种隐隐的压力围绕在和李江一样的大模型从业者周围。外界舆论从最初的追捧,变成猜测 “六小虎” 中哪家公司会扛不住先关门,或者被收购。
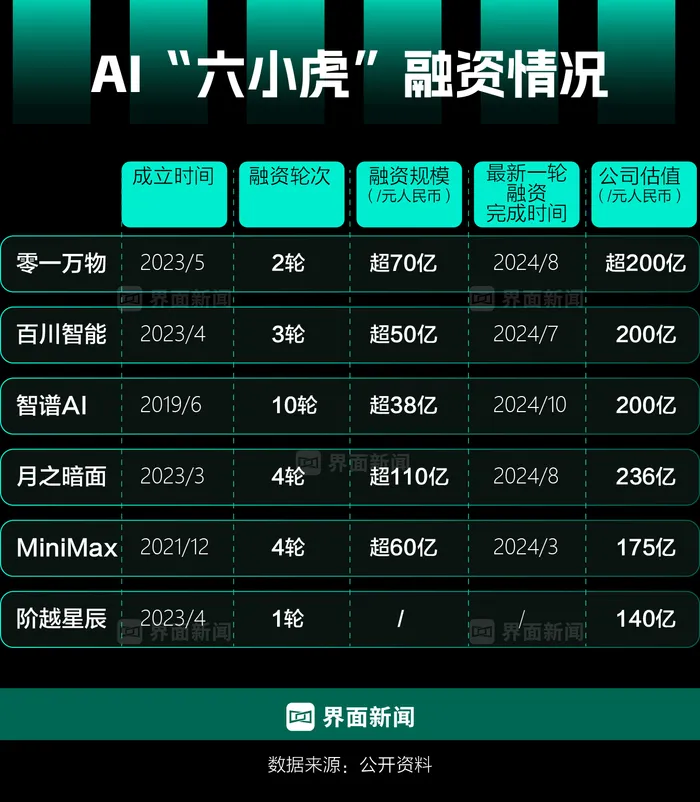
智谱 AI、百川智能、月之暗面、Minimax、零一万物、阶跃星辰这六家中国大模型初创公司,被业界冠以 “六小虎” 之称。过去一段时间,他们都拿到了数十亿乃至百亿人民币级别的融资,都在烧钱抢算力、抢人才,希望成为中国的 “OpenAI”。
随着大模型从业者们信仰的 Scaling Law(规模法则)遇到瓶颈,所有长远宏大的商业故事都要讲不下去了。“Scaling Law” 是有关模型性能随着参数量、数据量、计算资源等增加而变化的规律,此前几乎是抵达 AGI(通用人工智能)的唯一通路。
这种境况下,模型训练不得不脱离 “大力出奇迹” 的轨道。据《中国企业家》报道,百川智能 CEO 王小川近日接受其采访时提及,“去年焦虑买不到卡,今年焦虑有卡不知道该干嘛。” 很多团队把重心集中在一些微调(Fine-Tuning)工作上,让模型针对特定任务或领域进行优化。
李江所在的公司也是 “六小虎” 之一,外界的唱衰声不时传进团队成员的耳朵里。虽然大家还是坚信长远的光明,但现在仿佛都被乌云笼罩,看不清好的方向在哪里。
最终又是 OpenAI 将这片 “乌云” 吹散了大半。9 月 13 日,OpenAI 发布 o1 大模型,它改变技术策略,加入了强化学习和思维链,大幅提升了模型的推理能力,也将训练重点从预训练(pre-train)转向后训练(post-train)。
这被认为是大语言模型带领人类通往 AGI 的关键技术范式变革。
一名 AI 领域的投资人对界面新闻记者表示,大模型需要能够使用知识,而不只是具备知识。使用知识的能力是思维,而思维才是人类工作的核心价值。OpenAI o1 所展示的思维能力,是大模型从 “快思考” 向 “慢思考” 进化的关键指标。
而摆在国内创业者面前的选择题便是,要不要跟进?
考虑到每家公司的领导者对 AGI 的理解不同,团队技术实力存在差异,落地场景方向各有侧重,以及可跟注的筹码大小不一,国内大模型战局正在显现分水岭。
让所有人能继续抄作业
前段时间,零一万物创始人兼 CEO 李开复去了一趟硅谷,带回不少 OpenAI 的 “八卦”,还在直播间饶有兴致地讲了起来。
据他所述,外界期待已久的 GPT-5 训练得不太顺利,问题出在如何搞定一个 “十万卡集群” 上。风光面世的 OpenAI o1 只是被临时祭出的产物,这套方法原本没打算这么早公开。但为了吸引投资人继续投钱,这个动作不得不执行。
另一方面,OpenAI 也想借此炫技,让外界意识到,“你们只是看起来快追上我了,等我多露两手再看看。” 很快,OpenAI 宣布融资 66 亿美元,估值来到 1570 亿美元。
“其实我们还有很多好东西,只是没有发布。”OpenAI 的内部人员对李开复说,“因为我们一发布你们就会学。”
这名 OpenAI 人士担心得没错,这正是国内大模型领域的追赶状态,甚至成为一种技术学习的策略。
“我们一定要尽快追赶它,让它有压力。” 李开复说,“这样它就把一些好东西丢出来,我们大家就有更多的灵感了。”
o1 就是现阶段所有人的灵感。它提出了一个新思路。根据这家公司显示的技术信息,除了加入强化学习和思维链,它的本质变化是将 Scaling Up 的方法从预训练阶段转移到了推理阶段,让模型在 “推理时计算” 中获得更高的智能水平,也就是 Post-Training Scaling Law(后训练扩展律)在发挥作用。
这套新范式的力量真有这么大吗?在技术上如何理解 o1 范式可能加速 AGI 进程?
大模型行业上一个重要技术转变是从 Dense Model(稠密模型)到 MoE 架构(Mixture of Experts,混合专家模型)。这个变化本身带来的是速度提升,而没有太多能力提升,技术曲线从这里开始变缓和。但推理层强化学习可能改变这条曲线,它对应的是投入资源和所能达到智能上限的关系 —— 模型智能水平由此可能实现突破。
大佬们的观点是相近的。在 o1 发布一周后,阶跃星辰 CEO 姜大昕公开表示,o1 是大模型首次同时具备人类大脑 System 1 和 System 2 的能力,这是大模型开始具备归纳世界能力的关键一步。月之暗面创始人兼 CEO 杨植麟直言,o1 的主要意义在于提升了 AI 的上限,很大程度上证明了这套范式对于下一步 Scaling Up 初步可行。
换句话说,o1 代表的技术范式还不至于是 AGI 的直通车,但它的确是一列全新的特快车。
界面新闻记者从不同信源处了解到,Minimax 已经在推进类 o1 产品,预计最快明年一季度发布。月之暗面和阶跃星辰目前的主要精力可能仍是年底计划发布的多模态大模型,但 o1 也都在其各自的技术路线图上。
百川智能在强调医疗方向的落地场景后,暂时还没有透露出要加码 o1 方向的信号,不过内部一直有强化学习的训练经验。此外,多名受访者认为,智谱 AI 大概率会跟进 o1,而李开复则明确表示,包括零一万物在内,预计五个月后就会有不少类似 o1 模型的能力出现在各个公司。
“国内大模型公司都是抄 OpenAI 的路线,既然它蹚出了一条路,你也没有这么多试错成本,为什么不去 copy 它?” 李江认为,这个选择理所当然。
不比 GPT-4 简单
强化学习不是新东西。在此之前,很多大模型团队都在尝试强化学习这条路,只不过更快验证其正确性的依旧是 OpenAI。
“但凡是做过机器学习的,这个方法你一定会想得到,只是说愿不愿意投这么多资源去试这条路。” 李江说。
事实上,它还是今年诺贝尔化学奖其中两位获得者所在公司 DeepMind 的拿手好戏。这家公司用深度学习和强化学习的思路在很多垂直领域作出了突破贡献,比如 AlphaFold 和 AlphaGo。
至于 o1 为何现在才出现,一名大模型技术从业者对此解释道,一方面,模型参数的量级不同,这是决定性差距;另一方面,这当中的关键变量是强化学习和大模型的碰撞。如果以 o1 为结果,大模型和强化学习是一组由 “乘号” 连接的齿轮关系,但凡其中一种弱,整体都不会太强。
就技术而言,从业者认为 o1 比 GPT-4 更难,因为这当中的知识不会公开,团队必须自己尝试。“post-training(后训练)里面的秘密很多,而且越来越寡头化。” 前述受访投资人说,“在这场竞赛里,技术能力和技术 vision(视野)的占比变高了。”
也就是说,它需要天才的技术灵感,外加可落地的工程能力。
“最重要的是,首先有人能想得出整体的架构怎么做。” 李江表示,做这件事需要的是天才,而不是 “搭建一个 50 人团队”。相当于 OpenAI o1 现在是 “黑盒”,创业公司需要分配更多精力给强化学习,靠研究能力把 “黑盒” 变成 “白盒”。
工程上也还有大量的细节和难点。例如,算力方面,由于推理层的算力需求可能会出现爆发式增长,优化 AI Infra(基础架构)以快速降本的意义进一步凸显。数据方面,这套新范式相当于将一个 Agent(智能体)内置到模型中,因此,自动化数据训练的 pipeline(管道)也需要重新构建。
它同时提升了数据标注的难度和复杂度。生数科技首席科学家朱军在今年的云栖大会上谈论过,从科研的角度看,这当中过程监督的数据变得十分重要。它和直接从结果监督的数据不一样,是要对思考过程的每一步进行标注,这种数据由于需要专业人士投入,因而具备一定获取难度和高价值。
王小川也曾表示,他对 o1 的好奇有很多,例如拥有多少算力,以及多少领域专家。这大致对应 o1 训练数据的规模和质量。
Self-Play RL(自我博弈下的强化学习)虽然可以让模型自动生产数据来学习,但仍然需要人工的参与,并且是高质量的参与,其中就包括人工标注数据来告诉它结果好还是不好。
李江形容,数据标注既吃人力又吃学历,是一份看起来蓝领,但又特别要求白领的工作。“如果你没有模型聪明,你就没有价值,所以你要比模型的答案还好,而这份工作又特别枯燥,这样的行业专家不好找。”
o1 这条路未来可能遇到的最大瓶颈还是来自通用性,也就是模型的泛化能力。例如,o1 的数学、编程类能力尤其突出,但弱逻辑类的能力培养还有待解决。
强化学习中有一个关键环节叫做 Reward Model(奖励模型),用于评估 Agent 的行为表现,并指导其学习过程。在特定垂直领域,奖励机制可以写得清楚明晰,但面对更加泛化和开放的场景,Reward Model 将变得难以定义,这也是以 o1 范式在实现通用性过程中要突破的重要关卡。
“这是一个悬而未决的问题。” 李江说,这再次回到了各家科研能力的比拼上。即便是在公司内部,这种 “灵感” 现在也无法随意讨论,“因为这个事情太新了,‘灵感’要真金白银才能烧出来。”
事实上,大模型未来在提升强化学习模型的泛化性上会遇到什么困难,还不得而知,短期内能够复现某个垂直领域的国产 o1 就是一种胜利。开始习惯这个领域技术波动的李江就是这样想的,“在这个阶段,做长远的 Road Map(路线图)毫无意义。”
好学生的 “附加题”
云启资本合伙人陈昱每半年就要飞一趟美国,定期看看那边发生了什么,这让他对 o1 有一个更为冷静和理智的看法。
诚然,o1 代表了 OpenAI 在解决复杂问题上的探索,但它仍然有很大的局限:成本约为 GPT-4o 的 6 倍,使用次数的限制,较长的等待时间,以及一些简单问题仍然会出错的状况,目前的形态更像是给学有余力的好学生去做的 “附加题”。
答好这道 “附加题” 要投入多少资源?此前据腾讯新闻《潜望》报道,王小川在接受采访时曾预估称,“可能跟做个 GPT-4 差不多”。而朱啸虎给出的答案是,做 GPT-4 的科研至少要砸四五千万美金。
目之所及,国内大模型公司要跟进做 o1 必须满足两个硬性条件。一是拥有这笔可支配的资源。据另一名受访投资人透露,“六小虎” 当中,一些公司账上的钱可能不够。二是基础模型的性能水平门槛。李江的判断是,“至少要接近 GPT-4 的水平,不然不在牌局里。”
这意味着 “六小虎” 的下一步,有钱的可以继续跟注,没钱但想跟注的要继续找钱,如果都行不通,就只能找差异化。

不久前已经有行业传闻称,“六小虎” 中的两家正在逐步放弃预训练模型,缩减了预训练算法团队人数,业务重心转向 AI 应用。
一时间,“六小虎放弃大模型” 的说法甚嚣尘上。被外界猜测得最多的零一万物和百川智能,均迅速对外界进行了否认。
前述受访投资人对界面新闻记者表示,还没有看到实质性证据能够表明 “六小虎” 中有公司放弃了预训练,现阶段它们也没有理由放弃。他推测有一种可能是,有团队暂时性完成了基础模型的预训练,重心转向了后训练阶段。
“要知道‘六小虎’并不是 OpenAI,也不可能 OpenAI 的所有尝试都要去跟。” 这名投资人指出,“这当中需要有战略选择。”
这种战略选择的决定性条件,是掌舵者对 AGI 的理解。例如,有人认为多模态的理解与生成统一是 AGI 的必经之路,也有人认为,AGI 的关键仍然在于语言智能。这会导致不同的路线,大模型公司可能自此分化:视频模型,音频模型,高级推理等等。
除了创业公司,大厂也在积极跟进。有知情人士透露,目前,字节跳动和阿里巴巴都已有意向聚焦 o1 代表的技术方向,继续推动大模型的推理性能提升。不过,大厂的优势将更不明显。
李江直言,在上一个竞争阶段,文心一言、通义千问、混元、豆包等产品,并没有跟创业公司完全拉开差距。而在 o1 路线上,这种优势也许会更加微弱,因为它对算力资源的要求不如之前高,也更考验技术团队的灵活性。
大变革,但不一定激发大商机
投资人也听到不少所谓行业动荡的风声,但他们的大致体感是,在车上的都没有动摇过,不断动摇的都是没上车的。
“我们没有不看好过。” 前述投资人说,“外面所谓的舆论是我们两三年前就知道的事实,不觉得有什么预期上的偏差。”
之所以不动摇,来自于一个长期判断:AGI 能实现,绕不开大模型,而 o1 的出现说明了 AGI 可以实现,它的确提振了资本的信心。
这也将很大程度上决定大模型公司的融资命运。
“到 30 亿美元估值以后,大家就很难融了。” 陈昱指出,这是 “六小虎” 当前共同的困境。舆论之所以唱衰,主要原因也是估值和商业化程度不匹配。
“今年这几家融了三五亿美元以上的,明年都还可以活,因为大家一年大概烧 2 亿美元,加上之前的钱,活个三年是没问题的。” 陈昱说,“但他们得尽快解决商业模式的问题,烧钱是不可持续的。”
商业化,就是当前来自投资人最直接的拷问。需要认清的是,o1 这个技术上的 “大变革”,并不一定能激发大商机。
一方面,o1 所代表的 “模型即产品” 思路可能会革掉一批应用层公司的命。由于 o1 本身相当于内置了一个 AI Agent,很多简单的 Agent 不再有特殊价值。一名关注 AI 应用层的投资人对界面新闻记者表示,o1 对很多创业公司都产生了生死影响,比如只做 AI 编程的 Cursor AI,双方已经到了要比拼用户体验的阶段。
另一方面,o1 即便做出来,在产品上也没有直接的变现手段。最直观的改变可能在于,产品形态需要重新设计,从同步的方式变为异步。异步是指,用户发送请求后,模型会过若干分钟再反馈结果,而不是现在这种让用户干等的问答形式。
李江的看法有些悲观,认为即使国内公司做出 o1 这样的产品也不会对商业应用带来本质改变。“很多商业模式跟模型性能有关联,但又没有那么深的关联。”
这也是朱啸虎此前强调的,现阶段的模型性能提升不会对应用层带来实质影响,就算是模型准确率提升 50%,在多步推理之后叠加形成的错误率也是灾难性的。Minimax 创始人兼 CEO 闫俊杰也曾公开强调,模型错误率只有降到个位数才是可信赖的状态,才能为行业带来本质的变化。
以此来看,o1 可能是大模型技术上的分水岭,但用户很难感知到。“大模型是一个非常复杂的系统工程,o1 能产生的作用,只是在其中某个环节改变那么一点点东西,对全局没有那么大的影响。” 李江指出。
在 AGI 进程放缓时,o1 的出现几乎被视为 “全村的希望”,但它依然无法带大家挣到更多的钱,那它的意义到底是什么?—— 答案可能仍然在融资里。
在投资人视角,做 o1 的优先级不是最高,但它可以炫技和秀肌肉。在创业周期,这是融资的筹码。
作为创业者,李江很清楚,在砸钱推进模型通往 AGI 的过程中,创业公司有所图,也有牺牲。牺牲在于,一家大模型公司最终要卖的东西,可能跟模型性能本身并没有更深的关联。而它图的是,这个模型代表了它要销售的 AGI 愿景 —— 这个愿景既要销售给用户,也要销售给投资人。
“长期来看,你得靠它让大家相信这个故事 —— 它是在朝着 AGI 发展。” 李江说。
(受采访对象要求,李江为化名。)
(界面新闻记者李彪对本文亦有贡献。)
来源:界面新闻
 微信扫一扫打赏
微信扫一扫打赏 支付宝扫一扫打赏
支付宝扫一扫打赏





